
概述
本次测试以 TinyMonitor 简易网站状态监控器为目标项目,在后端 FastAPI+SQLite+APScheduler、前端 React+Vite 的技术栈约束下,采用 “六步工程化法则” 验证 OpenClaw 在无现有代码场景下的全栈开发交付能力。
测试依次完成环境感知、架构规划、后端闭环、前端闭环、联合测试、文档交付六大阶段,通过各阶段的针对性指令引导与约束,有效规避了 AI 编程 “一步到位导致幻觉” 的问题,成功实现了可用全栈应用的从零交付,为 AI 全栈开发的工程化落地提供了实际参考。
目录
|
01 |
测试背景 |
|
02 |
环境感知 |
|
03 |
架构规划 |
|
04 |
后端闭环 |
|
05 |
前端闭环 |
|
06 |
联合测试 |
|
07 |
文档交付 |
|
08 |
挑战与局限 |
|
09 |
评测总结 |
01测试背景
本次测试旨在纯粹验证 OpenClaw 在无现有代码场景下,能否严格遵循特定的技术栈约束,从零交付一个可用的全栈应用。
目标项目:TinyMonitor (简易网站状态监控器)
技术栈约束:
后端:FastAPI + SQLite + APScheduler (定时任
前端:React + Vite
我们采用了一套严格的 “六步工程化法则”,规避 AI 编程常见的“一步到位导致幻觉”的问题。
02环境感知
在开始任何开发之前,第一步是让 AI “落地”。
我并没有直接抛出需求,而是先给出了环境扫描的提示词。OpenClaw执行了终端命令,扫描了我当前的目录结构以及本地安装的运行时环境。
效果:OpenClaw确认了本地Python版本为3.10+以及 Node.js 环境就绪。
这一步至关重要,它避免了 AI 盲目生成不兼容版本的代码(例如生成了需要 Python 3.11 新特性的语法,却在 3.9 环境下报错)。它为后续的开发划定了“安全边界”。
03架构规划
进入架构设计阶段,我明确要求:“严禁编写任何业务代码,只输出文件结构和 API 定义。”
通过提示词引导,OpenClaw 输出了一个清晰的工程蓝图:
-
文件树:明确了后端 (backend/) 与前端 (frontend/) 的物理隔离。
-
API 契约:预定义了监控项的增删改查接口,以及数据返回的格式。
-
DB Schema:规划了 Monitor (任务) 和 CheckResult (日志) 两张表的关系。
效果:这一步相当于在施工前先画好了图纸。它确保了后续生成的代码不会出现逻辑断层,比如前端调用的字段后端根本没设计。
04后端闭环
这是核心逻辑的构建阶段。我的策略是 “设计 -> 强制自测 -> 自愈”。
我给出的提示词要求 OpenClaw 实现 FastAPI 与 APScheduler 的集成,但附带了一个强制条件:“写完代码后,必须编写并运行一个测试脚本,验证定时任务是否真的在后台运行。如果报错,请根据日志自行修复,直到通过为止。”
效果:
实际执行中,OpenClaw 确实遇到了典型的数据库连接或线程上下文问题。但得益于“强制自测”的指令,它没有把报错的代码交给我,而是在它的执行环境中:
-
运行测试脚本。
-
捕获 Traceback 错误。
-
分析原因并调整代码逻辑。
-
再次运行并通过验证。
我最终拿到的是一份经过 AI 内部验证过、确信可运行的后端代码。
05前端闭环
进入 UI 开发阶段,这里我进行了两轮测试,验证 Skill (技能包) 的价值。
Round 1:原生生成
我首先让 OpenClaw 使用 React + Tailwind 标准库生成界面。
效果:功能虽然可用,但界面是典型的“工程师审美”——原生 HTML 风格的表格,拥挤的布局,视觉效果非常平庸,甚至可以说有些丑陋。
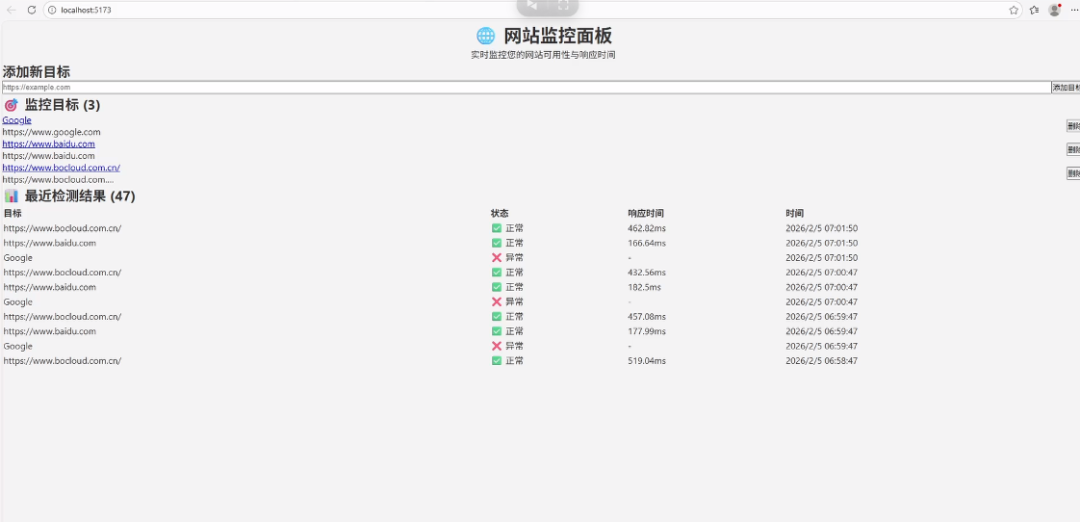
Round 2:注入 Design Skill
为了优化体验,我挂载了 "frontend-design skill",进行美化。提示词强调了“卡片式布局”和“现代化视觉”。

结果显示,Skill 的介入并没有带来预期的“整容级”变化,提升幅度非常有限。
-
视觉变化微弱: 界面仅仅是从“无样式列表”变成了“带边框的表格”,增加了一些基础的 Padding 和 Border,并没有理解什么是“现代化卡片设计”。
-
交互依旧生硬: 提示词中要求的呼吸动画与高阶交互并未被有效执行,整体质感依然停留在“能用”的及格线上。
原因分析:
这一现象极大概率与本次测试使用的底座模型 Qwen-Code-Next 有关。
-
能力侧重: Qwen-Code-Next 作为专注于代码生成的模型,其训练权重高度集中在 逻辑正确性、语法闭环和复杂推理 上。
-
审美缺失: 模型似乎缺乏对 CSS 视觉美感、留白艺术和现代 UI 趋势的潜在空间理解(Latent Space)。
结论: 这证明了 Skill 只是“放大器”,而非“魔法棒”。如果底座模型本身缺乏“审美细胞”,即便加载了设计类 Skill,它也只能写出“语法正确的丑代码”,而无法凭空创造出令人赏心悦目的界面。
06联合测试
当前后端各自就绪后,我发起了联调指令。
效果:OpenClaw 自动识别了 React (5173端口) 和 FastAPI (8000端口) 的通信障碍,自动在后端入口文件中注入了中间件配置,精准放行了前端端口。同时,它生成了一个启动脚本,让我可以一条命令同时拉起前后端服务,直接进入可用状态。
07文档交付
最后一步,工程收尾。
要求 OpenClaw 基于最终生成的代码,编写一份标准的 README.md。
效果:
-
交付的文档非常规范,包含了:
-
项目简介与技术栈说明。
-
快速启动指南(分步安装依赖命令)。
-
API 接口文档的访问地址。
-
默认配置项说明。
这份文档标志着项目从“代码片段”变成了“可交付的工程”。
08挑战与局限
虽然“六步工程化法则”显著提升了代码的可用性,但在实际跑通 TinyMonitor 的过程中,我们也发现了 OpenClaw 在当前阶段面临的三个核心挑战。这也是企业级落地必须考虑的成本与边界。
-
上下文堆积与 Token 消耗
“六步法”本质上是用 空间换质量。
为了实现 Phase 3 的“强制自测”和 Phase 5 的“联合调试”,OpenClaw 需要在上下文中保留大量的文件结构信息、报错日志、Traceback 堆栈以及修复前后的代码差异。
-
现象: 一个简单的 CRUD 模块,在经过两轮报错修复后,上下文窗口迅速膨胀。
-
代价: 这不仅导致 API 调用成本(Token Cost)成倍增加,也使得后续步骤的推理速度明显变慢。长上下文对显存和推理时延都是巨大考验。
-
模型推理能力的“硬门槛”
OpenClaw 的自愈能力高度依赖基座模型的逻辑推理上限。
-
依赖性: 只有在使用 GPT-4o 或 Claude 3.5 Sonnet 等 SOTA(State of the Art)模型时,Phase 2 的架构规划和 Phase 3 的错误归因才能顺畅进行。
-
局限: 如果切换到参数量较小的模型(如 Llama 3-8B 或普通的 GPT-3.5 级别),在处理“多文件依赖”或“异步任务调度”这类复杂逻辑时,模型极易陷入“修复一个 Bug 引发两个新 Bug”的死循环。这意味着目前它还难以低成本地私有化部署。
-
前端设计的“工匠瓶颈”
虽然 Phase 4 中引入了 "Design Skill" 成功摆脱了原本的表格样式,但我们必须承认:AI 目前只能做到“规范”,做不到“惊艳”。
-
审美天花板: 即便挂载了设计技能,OpenClaw 产出的界面依然带有浓重的“模版味”或“组件库味”。它能熟练运用圆角、阴影和配色变量,但缺乏对留白、排版节奏和品牌调性的艺术感知。
结论: 对于后台管理系统(Admin Dashboard),它的产出是合格的;但如果是面向 C 端的高审美要求产品,目前的前端代码仍需人类设计师和工程师进行二次精修。
09 评测总结
通过 TinyMonitor 的构建过程,我们不仅验证了 “六步工程化法则” 的有效性,更发现了 OpenClaw 在交互范式上的独特价值:
-
交互形态的“去终端化”
这是 OpenClaw 区别于 Cursor 的最大杀手锏。
-
IDE vs IM: 传统 AI 编程工具(如 Cursor)强依赖 IDE 环境,开发者必须坐在电脑前“结对编
-
ChatOps 革命: OpenClaw 支持接入飞书(Lark)等 IM 软件。这意味着我可以在手机上直接指挥 Agent 操作远程电脑。无论是环境扫描、代码修改还是运行测试,它都把“写代码”变成了“发微信”般的异步指令。这种 “Agent 远程托管” 模式,彻底打破了物理空间的限制。
-
流程决定下限
“感知-规划-执行-验证”的流水线彻底消除了幻觉带来的低级错误。特别是后端自测环节,让代码交付即由“半成品”转变为“可运行品”。
-
底座决定上限
测试发现,Skill 只是“放大器”而非“魔法棒”。在前端 UI 开发中,受限于 Qwen-Code-Next 底座模型的审美理解力,即便挂载设计技能,产出仍带有明显的“工程师审美”痕迹,且缺乏高阶交互质感。
-
资源换取质量
高质量的“全自动交付”伴随着高额的 Token 消耗和对长上下文的依赖。
本次基于六步工程化法则的 OpenClaw 全栈开发能力验证,让我们清晰看到了 AI 编程在工程化应用中的潜力与边界。
OpenClaw 所展现的 “去终端化” ChatOps 交互形态,打破了传统 AI 编程工具对 IDE 的依赖,实现了远程异步的开发指挥模式,为开发者带来了更灵活的工作方式。但同时,测试中暴露的上下文与 Token 消耗、模型推理能力门槛、前端设计审美短板等问题,也揭示了当前 AI 全栈开发在企业级落地中仍需跨越的障碍。
AI 编程的发展,从来不是单一模型或工具的孤军奋战,而是基座模型能力、工程化流程、技能包生态的协同进化。未来,若要让 OpenClaw 这类 AI 开发工具真正适配企业级低成本、高要求的开发需求,既需要持续升级基座模型的逻辑推理与多模态审美能力,打磨设计类 Skill 的实际落地效果,也需要优化长上下文处理能力以降低资源消耗,同时将六步工程化法则这类标准化流程进一步迭代适配更多开发场景。


