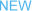

近日,在中国电子技术标准化研究院主办的2025年云产业和标准应用大会上,江苏博云科技联合创始人、高级副总裁崔骥做演讲分享,他基于大量客户实践,直指当前AI私有化部署的核心痛点:“一台两三百万的机器买进来,空空荡荡就部署了一个模型,这是一种资源很浪费的状态。” 他指出,AI技术栈的不成熟与异构环境的复杂性,正使企业陷入 “部署难、管理乱、利用率低” 的困境。

难题一:异构GPU林立,统一管理成奢望
崔骥回顾,从早期单一的英伟达GPU,到近年来国产算力体系涌入,客户机房已成为异构硬件“综合体”。“我们基本上掉在泥坑里爬,”他形象地描述了适配过程的艰辛,“没有一种通用方案能适配所有GPU,必须每家接口去对接,反复打磨。”
这种异构环境导致企业需要维护多套管理栈,算力资源分散形成“孤岛”,无法统一调度。博云ACE引擎的核心能力之一,就是通过深度适配,将不同CPU、GPU、DCU等各类算力卡统一接入与管理,为上层应用提供一个一致的算力界面。
难题二:资源静态分配,昂贵GPU大量空转
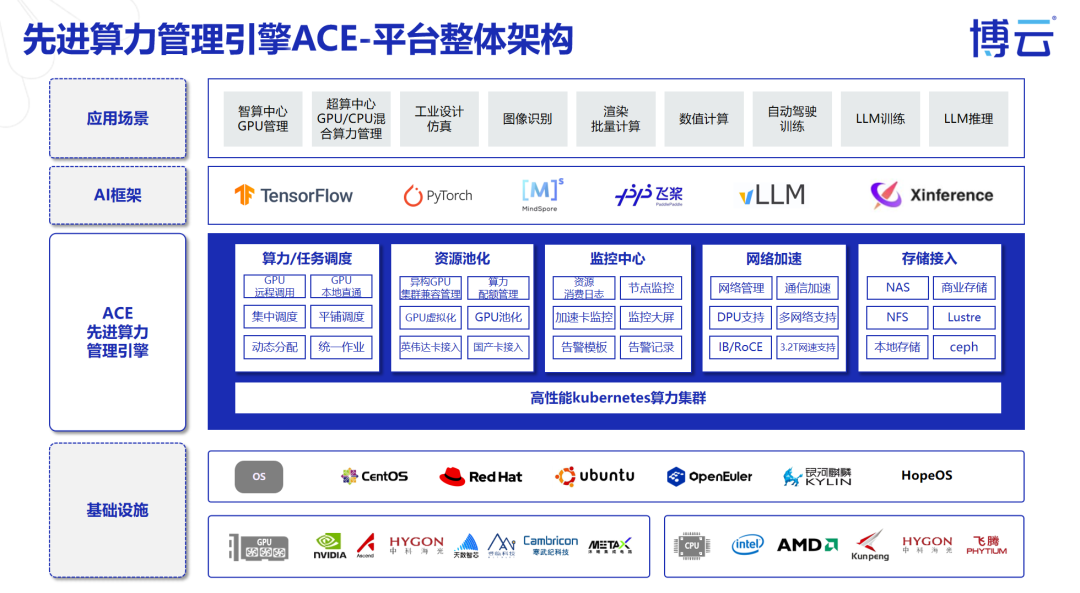
“一个最基本的智能体应用,比如知识库,也需要对话模型、量化模型、重排序模型等多个模型协同工作,”崔骥解释道,“如果按传统‘一张卡一个应用’的模式,资源浪费极其严重。”
ACE通过成熟的算力池化技术,能将一张物理GPU卡安全地切分为多个虚拟GPU,并允许跨节点的GPU组成统一资源池。
这使得“一卡多模”(多个小模型共享一张卡)和“多卡一模”(一个大模型分布式占用多张卡)得以在同一平台上无缝实现。

“它能将一张物理GPU卡细粒度切分为多个vGPU,实现“一卡多用”。一个小模型不再需要独占整张卡,可以仅分配0.1或0.4张卡的计算资源,极大提升了单台服务器的应用部署密度。
难题三:部署全靠摸索,运维团队疲于奔命
AI技术栈还不够成熟,模型部署失败后,定位问题极其困难。博云调研结果显示,客户反映超过50%的模型部署失败,最初都源于资源配置的不匹配。
“什么模型在什么卡上最少需要多少资源?资源应该分配多少?环境变量如何配置?框架版本是否兼容?管理员一天到晚都在解决“如何把模型拉起来”的问题,其他故障都无暇顾及。
为此,ACE平台使用资源规格规避资源估算的摸索,一个资源规格里面包含了加速卡的类型(支持虚拟加速卡规格)、数量、CPU核数、内存大小;用户创建任务选择资源的时候,选择管理员配置的运行某类模型的最低算力规格,再在此基础上根据业务需要进行弹性扩容,可以大幅降低管理工作试错的工作量。
崔骥总结道,博云ACE平台直面AI落地中最实际的三大挑战:通过统一接入管理异构算力,通过池化划分提升资源利用率,通过资源规格简化部署流程。这套基于博云多年容器技术积累的解决方案,可有效帮助企业将复杂的算力环境转化为高效、易用的生产力,让企业真正从AI中获得业务价值。


