
为什么要进行大模型微调
大模型微调是将预训练模型适配到特定任务或领域的关键技术,正常情况下大模型通过海量通用数据训练获得广泛知识,但其参数和表征空间面向通用场景,难以直接适配垂直领域或复杂任务。例如在通用医疗问答模型在具体病症诊断任务中可能缺乏细粒度知识。针对这种情况,微调可调整模型参数,使其更贴合特定领域的数据分布。在法律咨询场景中,将法律文本适配到预训练模型,能显著提升合同条款解析的准确率。
大模型微调是连接通用能力与垂直应用的桥梁,其核心价值在于将预训练模型的“通才”转化为“专才,通过技术选型(如LoRA、部分参数、全参)实现最优投入产出比以及快速适配需求变化,支撑持续迭代,随着AI的持续发展以及对于垂直应用场景需求的提升,大模型微调将逐渐成为大模型应用的核心环节。
大模型微调的应用场景
1. 垂直领域知识适配:

场景:
微调后模型可理解医学术语(如ICD-10编码)和诊断逻辑,用于电子病历分析。基于PubMed文献微调的BioBERT,在疾病分类任务中准确率提升12%。

场景:
适配合同条款解析、风险预警等场景,如微调模型识别SEC文件中的潜在违规行为。
2. 任务深度优化

通过数学题集微调,增强模型逻辑推理能力。

风格调整,如新闻稿的正式语气,自动转为社交媒体文案的轻松风格。
3. 数据安全合规

使用本地化数据微调模型,避免内部敏感信息外泄,如银行客户数据训练风险评估模型。

调整模型输出以满足GDPR等数据保护要求,例如自动过滤隐私信息。
大模型微调的方式和资源需求
目前博云BMP支持全参数微调、LoRA和部分参数微调三种微调模式,可以根据客户的不同场景来满足大模型微调的需求。

全参微调是指对预训练模型的所有参数进行更新,使其适配下游任务的一种微调方法。与参数冻结或部分微调(如LoRA)不同,全参微调通过调整模型所有权重来捕捉任务特定模式,通常需要较大的计算资源和数据量。
LoRA是一种针对大模型的高效微调技术,其核心思想是通过低秩矩阵分解,在冻结原始预训练模型参数的基础上,引入少量可训练参数,从而在降低计算和存储成本的同时保持模型性能。
部分参数训练是一种分层选择性训练的模型适配方法,通过冻结预训练模型的部分参数(通常为底层或中间层),仅微调顶层或特定任务相关层的参数。其核心思想是利用预训练模型的通用表征能力,减少冗余参数更新,同时降低计算资源消耗。
不同微调模式的不同维度对比表:

大模型微调流程
01数据集准备
对于平台而言,微调所用的数据集需要满足如下格式:
{
"instruction": "使用XXX框架实现XX功能,要求为XX",
"input": "",
"output": "对应代码"
}
这样模型在微调的过程中就可以进行识别,博云会提供对应数据转换服务,把客户提供的数据集转为以上要求的JSON文件。
例如:我们根据在线教育客户提供的一个题库,将题库转为以上格式的JSON文件:

JSON文件创建好以后,保存到本地,上传到BMP里面的数据集,如下图所示:


02微调操作流程
进入BMP界面,选择大模型微调
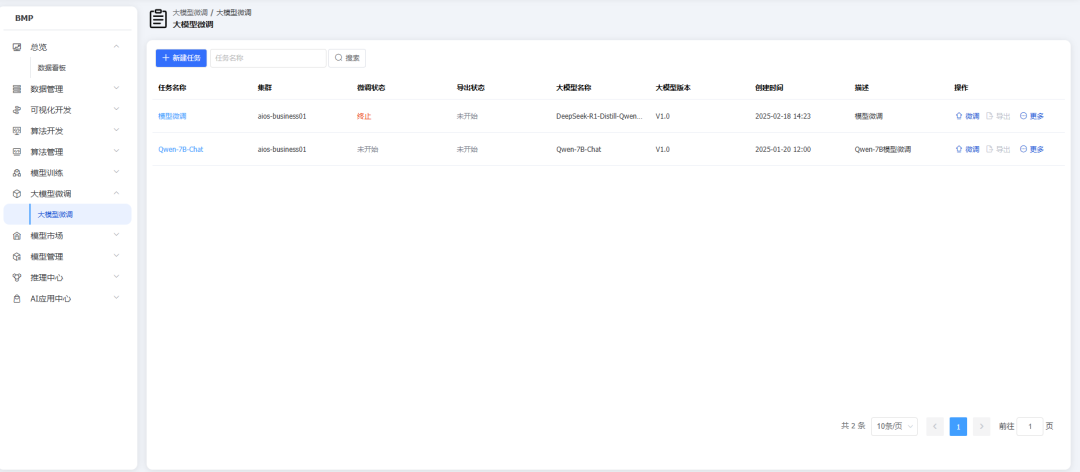
点击创建微调任务来创建微调任务,选择需要微调的大模型,根据微调的模型配置对应的算力资源


算力资源匹配完成以后,就可以进入微调面板进行微调
![]()

根据微调需求选择对应的阶段、微调方式,根据以上要求准备好相应的数据集即可。
03微调参数配置建议
LoRA微调核心参数
秩(lora_rank):建议 8-64,简单任务选择小秩(如8),复杂任务需≥16以保留表达能力12。
Alpha(lora_alpha):通常设为秩的整数倍(如秩8时alpha=16),控制权重更新强度,值越大对新任务适应能力越强1。
Dropout(lora_dropout):小数据场景设为 0.3 防过拟合,大数据场景可设为 01。
通用参数
学习率:建议 1e-5 到 5e-4,比全参数微调更低,避免破坏预训练知识2。
批处理大小:显存不足时可用梯度累积(如batch_size=2 + 梯度累积步数8),等效batch_size=161。
适用场景
资源有限、需快速迭代的任务(如对话生成),支持多任务共享基础模块。
全参数微调关键参数
学习率:推荐 1e-6 到 5e-5(比LoRA更低),大型模型(如百亿参数)优先小学习率。
训练轮次:大数据集(百万级样本)建议 5-10 轮,小数据集需早停防止过拟合。
显存需求:至少需A100(80GB)级别GPU,支持大batch_size(如32)。
优化策略
混合精度训练:启用 bf16 或 fp16 加速训练,同时降低显存占用。
适用场景
数据充足、任务复杂(如领域迁移),需全面调整模型参数。
部分参数微调核心参数
冻结层数:通常冻结底层(如前20层),仅微调顶层全连接层,保留通用语义特征。
学习率:可略高于全参数微调(如 5e-5),因高层参数需快速适应任务。
训练轮次:推荐 3-5 轮,小数据集也能快速收敛。


