
模型介绍
Yolo模型是一个专门用于目标检测任务,即在图像中识别和定位多个对象的模型。
YOLO的基本特点:
速度快:YOLO是一种端到端的算法,可以在一次前向传递中同时检测多个对象,因此速度非常快,适用于实时应用。在GPU上运行时,YOLO可以实现较高的检测速度。
准确率高:YOLO使用整个图像进行预测,能够捕获全局上下文信息,从而提高检测准确率。随着版本的迭代,YOLO的检测精度也在不断提升。
可解释性强:YOLO使用单个神经网络进行预测,可以直接输出边界框的坐标和类别概率,易于理解和解释。
适用性广:YOLO可以应用于各种不同的目标检测任务,包括人体姿态估计、车辆检测、行人检测等。
Yolo应用领域
由于快速、准确的特性,YOLO在众多领域得到了广泛应用:
-
实时视频监控
-
自动驾驶汽车中的障碍物检测
-
无人机导航
-
体育赛事分析
本文将演示如何在AIOS上部署和训练Yolo。
运行环境
Python:3.11.8
torch:2.2.1+cu121
ultralytics:8.0.196
GPU:NVIDIA GeForce RTX 4090 NVIDIA
下载模型:yolov8n.pt
准备工作
AIOS平台的算法开发模块,是云原生的资源使用和开发工具链的集成,开发者可选择Pycharm、Notebook或Vscode工具进行所有的开发工作。
同时,开发环境资源分配采用虚拟GPU(vGPU)技术,将物理GPU资源虚拟化,从而在多个虚拟机之间共享资源,降低成本的同时提高了资源利用率。并且vGPU技术提供了强大的隔离性,确保每个虚拟机获得的GPU资源是独立的,从而避免了资源争用和冲突。
这里我们选择Notebook工具进行演示。
新建一个notebook任务,选择具备Pytorch框架的预置镜像,分配算力和资源。

任务创建后,启动notebook,新建一个Jupyter Notebook文件,导入所需要的ultralytics库和模块。

模型应用
所需的环境准备好之后,就可以使用Yolo模型识别图片信息。目前我们使用的yolov8模型可以识别动物、汽车、手机等几十类物体。
首先,上传需要识别的图片,然后使用模型进行标注。
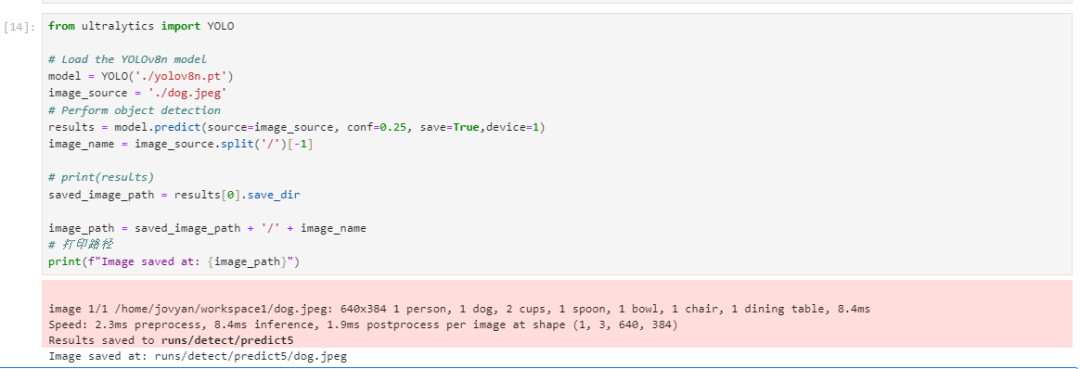
标注结束后,会自动生成一个新的路径存放结果图片。
查看结果图片:

模型训练
目前能够识别的种类远不能满足我们的需求,所以我们需要在自定义数据集上训练一个能满足不同需求的模型,以桥体识别为例。
1. 数据集处理
在AIOS平台上创建一个目标检测的数据标注任务,对训练集和验证集的图片进行标注。
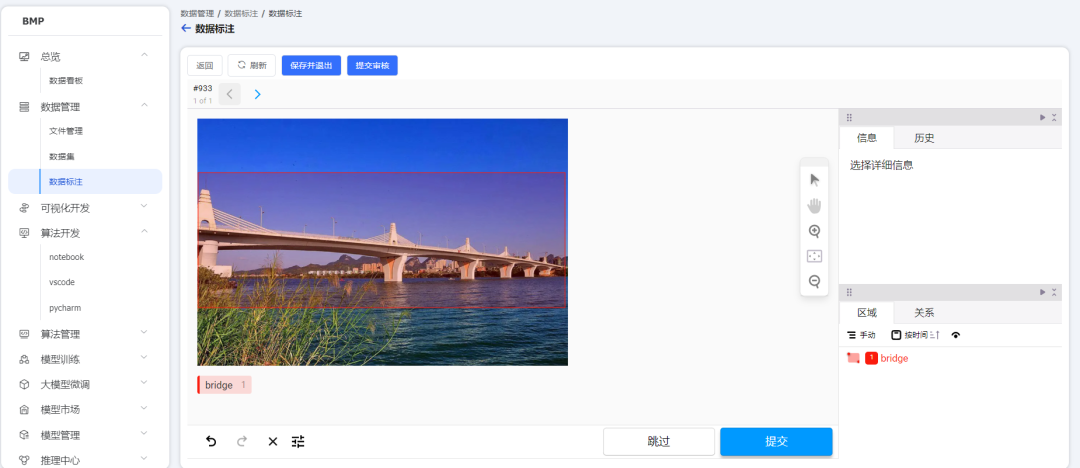
图片全部标注完成后,AIOS平台可以直接将数据集以能够被Yolo模型使用的格式导出。
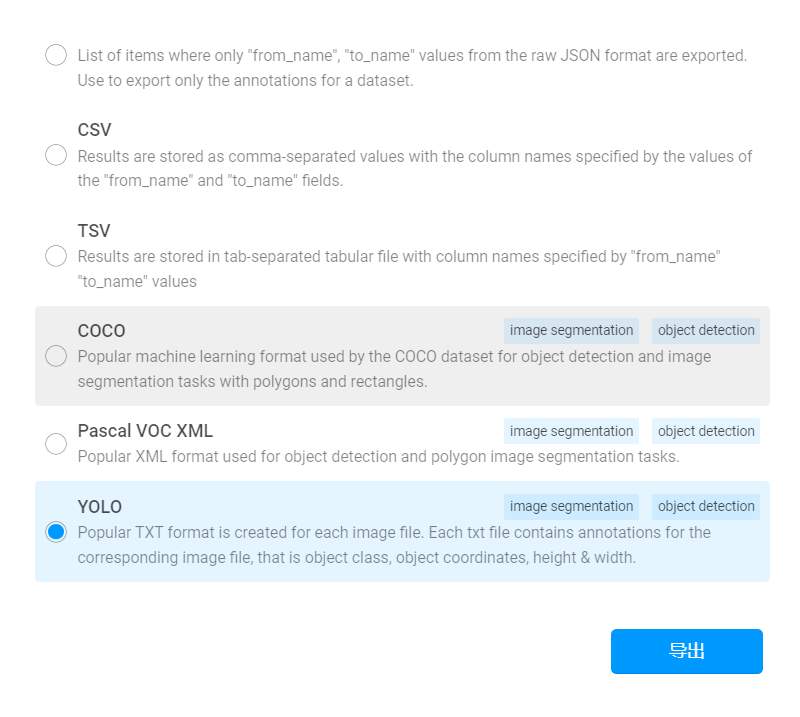
数据集导出后,使用数据集管理功能,保存标注前后两种格式的训练集和验证集,并且在notebook任务中直接使用。
2. 训练模型
创建一个yaml格式文件,写明数据集路径以及识别的标签数量和名称:
path: ./datasets
train: ../train/images
val: ../valid/images
nc: 1
names: ['Bridges']
文件保存后,开始训练模型,设置批量大小和训练周期数。
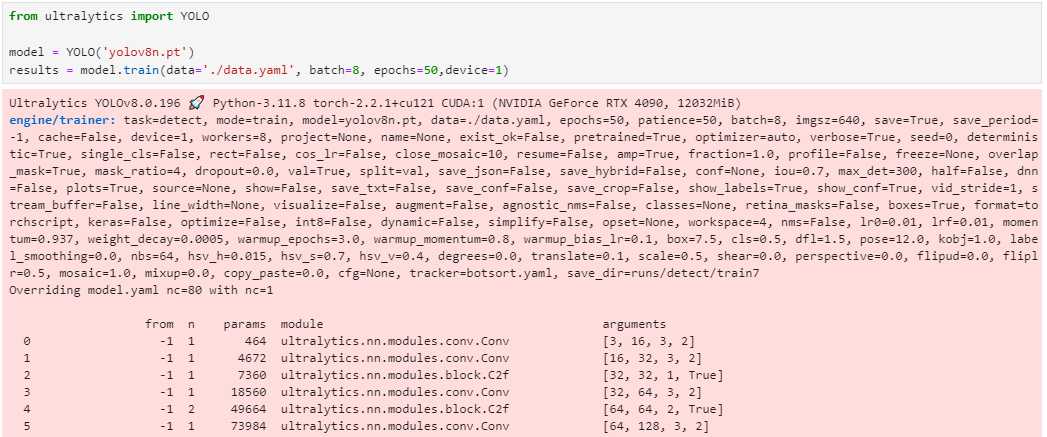
本次演示批量大小batch=8,训练周期数epochs=50
训练结束后,会自动生成一个新路径来存放训练好的模型以及训练过程中的性能指标可视化图片。

3.测试模型
加载新的训练模型,验证模型的效果。
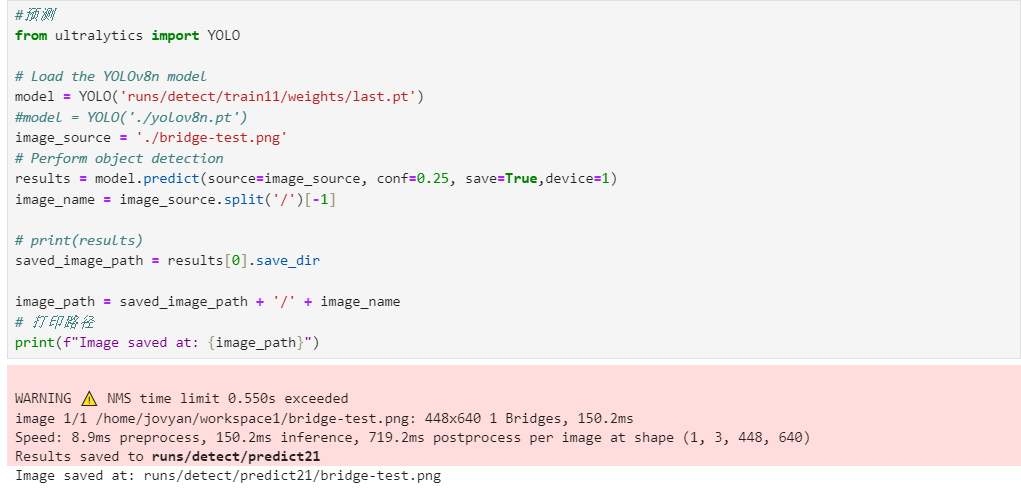
查看标注结果:

标注结果:桥体的置信度0.85
模型推理
将训练完成的模型直接导入到模型仓库,并使用该模型创建在线推理任务。创建推理任务后,平台会自动生成外部调用的API接口并提供传参入口,用户只需填写相关的参数就可以直接利用平台进行快速推理。
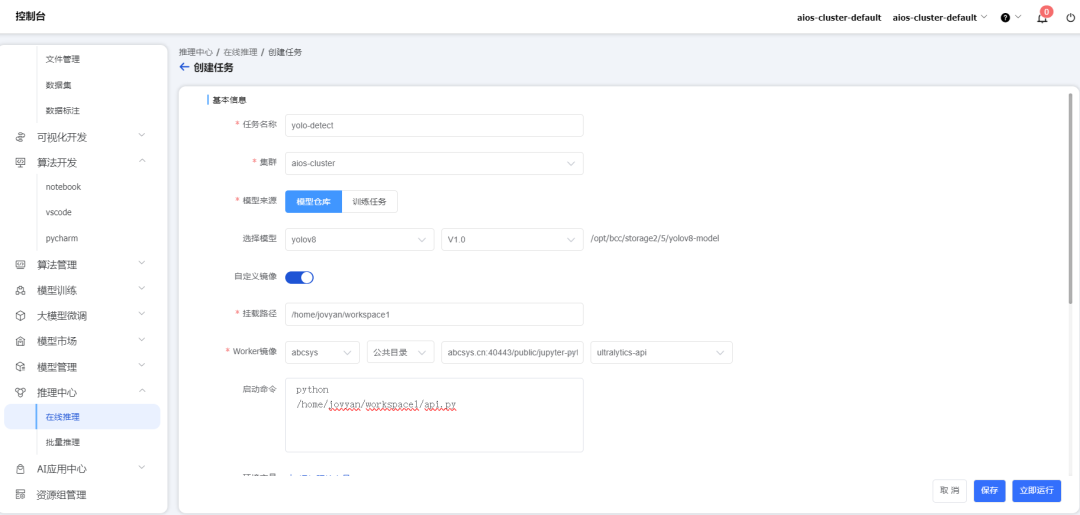
添加自定义参数image_source,填写所被识别图片的路径。
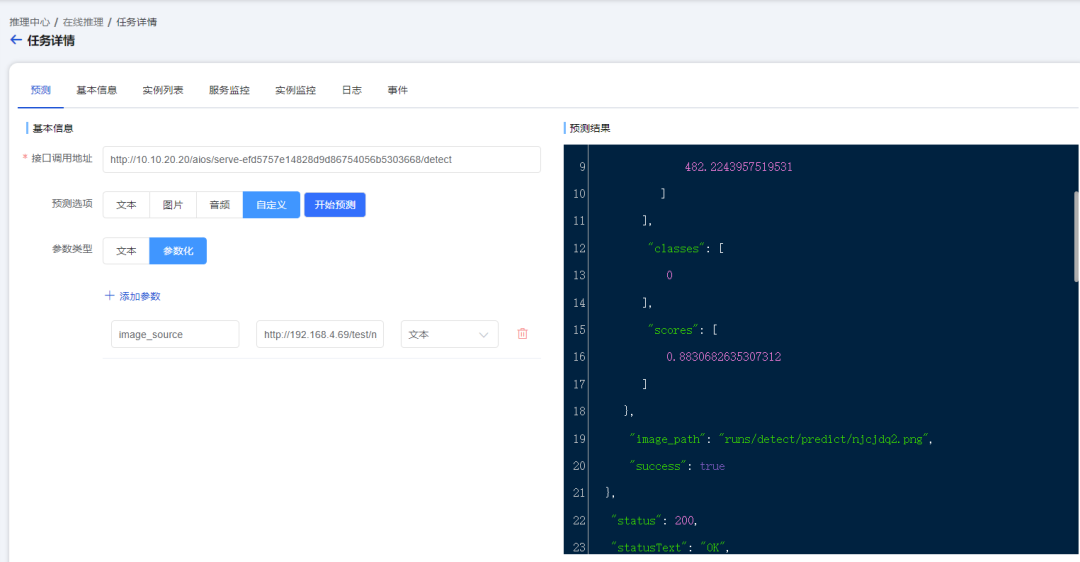
点击开始预测,右侧结果框会显示标注结果的置信度、存放路径等信息,查看结果图片:
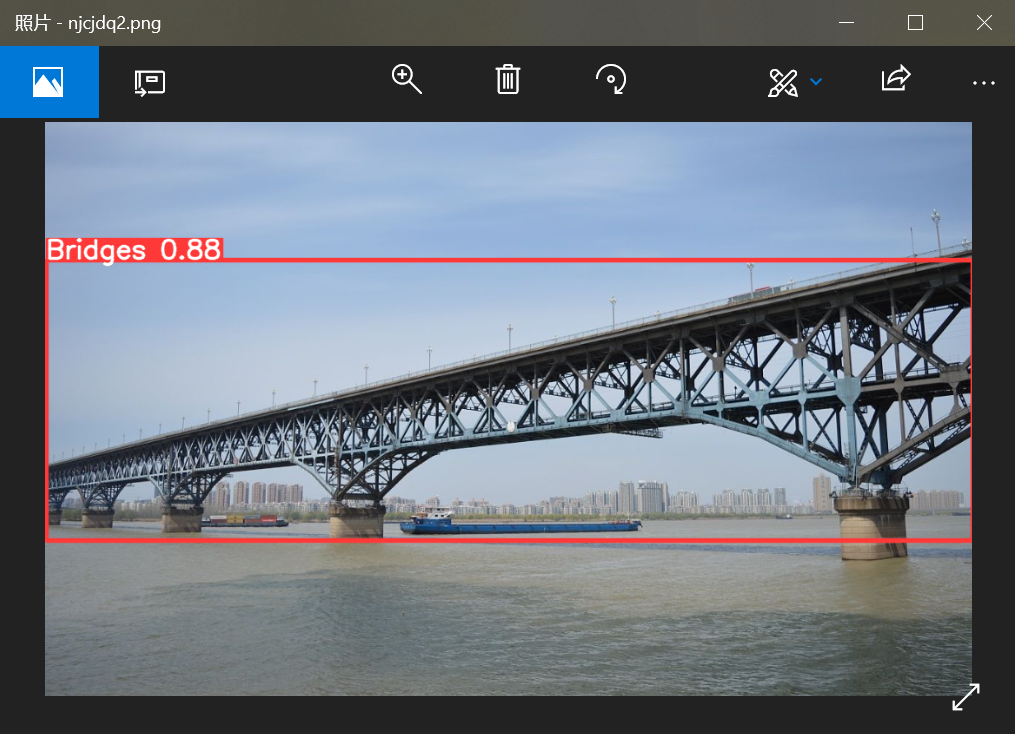
标注结果:桥体的置信度0.88
亮点
AIOS平台为Yolo模型提供了稳定而又高效的训练环境,能够覆盖数据标注、算法开发、模型训练和模型推理的全生命周期。
平台的数据标注模块能够让用户轻松地标注自定义数据集,并且可以直接将数据以能被Yolo模型训练的格式导出,省去了安装标注工具、格式转换等步骤,提高了工作效率;
另外,平台的算法开发模块不仅提供了独立的训练环境,还能够灵活地调用资源,利用性能监控工具实时监控性能指标,让用户可以得到实时反馈。
总而言之,AIOS平台不仅提高了数据标注的工作效率,节省了前期准备的时间,还提供了独立的训练环境和实时监控功能,为AI模型打造了一个方便且灵活的使用平台,为人工智能技术的持续创新提供强有力的支持。
相关产品介绍
AIOS是博云专为AI应用推出的企业级一站式人工智能操作系统,屏蔽底层异构算力差异,面向大规模分布式计算,在计算、网络、存储、调度等基础能力全面增强,为AI应用提供稳定、高效、极简的底层支撑能力。同时AIOS支持主流的分布式AI深度学习框架,可满足算法、模型、组件的可视化开发,覆盖数据标注、算法开发、模型训练、模型推理的全生命周期。AIOS可以帮助企业和开发者自主构建人工智能业务,助力企业保持行业领先能力。
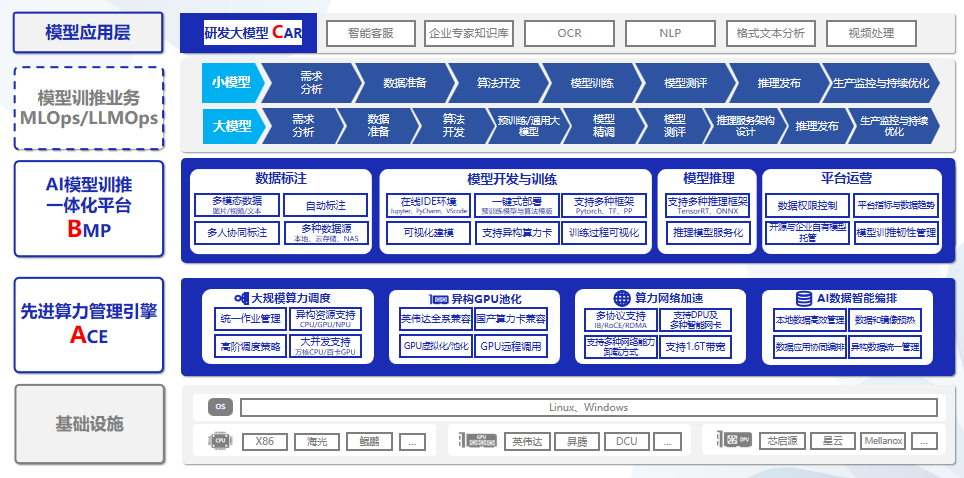
强大的底层掌控能力
AIOS的核心在于其强大的ACE算力引擎,支持高达5000个节点的稳定调度,以及异构GPU池化管理,确保了多租户算力的强隔离和全方位监控。
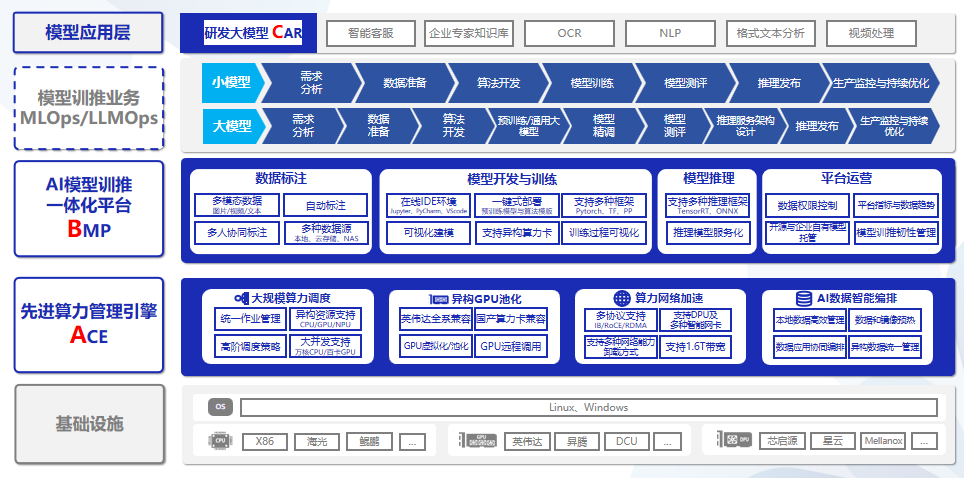
功能特性
覆盖深度学习业务全流程,加快模型从研发到上线速度。
深度学习训练任务通常包含多个阶段,从数据采集、算法开发、模型训练、超参调整、模型管理与部署等,AIOS提供全流程支持。
快速部署计算环境并启动训练任务,提高研发效率
深度学习框架和模型众多,依赖各不相同,对开发环境的要求比较复杂, AIOS可以实现资源和工作环境的隔离及快速部署。
支持数据集统一管理,提升数据标注效率
数据集种类众多,数据标注工具不一。AIOS支持多种标注场景,覆盖文本、图片、音频和视频标注,支持人工标注、协同标注、智能标注等多种业务场景,极大提升数据标注效率。
支持多种建模方式,方便算法工程师快速构建复杂模型
支持交互式建模,内置Jupyter、VScode和Pycharm建模工具,方便算法工程师对代码进行调试;支持通过拖拉拽方式实现可视化建模,平台内置多种算法组件,极大降低建模门槛。
训练过程可视化,掌握训练进度及质量
深度学习模型训练周期较长,训练结束后才发现模型质量问题。借助AIOS,可以实现对训练过程实时监控并可视化训练过程,实时观测损失函数值的日志、训练误差或测试误差等。
动态分配 GPU 资源,充分利用资源,提高资源利用率
支持 GPU 资源细颗粒度调度能力,最低可划分1%资源。同时支持众多国产GPU算力。单一计算集群可以统一管理异构的多种GPU算力。
全面的集群监控管理,实时掌握 CPU/GPU 资源使用情况及运行状态
实时监控集群的使用情况,合理安排训练任务;及时发现运行中的问题,提高集群的可靠性。
方案优势概览



