
近年来,大型语言模型在软件开发领域中扮演着越来越重要的角色。它们不仅能够辅助开发人员提高编码效率,还能改善代码的质量和可维护性。在实际的代码开发过程中,大型语言模型展现出了许多强大的功能和应用场景。
本文将介绍博云研发大模型在四大场景下的十几种核心能力,并通过一系列场景来展示大模型对于代码辅助开发的实践。
问答场景
在问答场景中,博云研发大模型可以根据开发人员的自然语言描述,生成相应的代码或可视化页面。例如,开发人员可以通过简单的描述来要求模型生成特定功能的代码,或者创建特定样式的网页界面。
对话生成代码
当我和同事正在讨论一个新功能的实现方式,但在讨论中我们意识到需要编写一些代码来支持这个功能。通过与大型语言模型进行自然语言对话,简要描述了我们需要的功能和代码结构,模型随后生成了相应的代码片段,让我们可以立即使用。
Q:我需要一个函数,用于获取k8s某个命名空间下的所有service的信息。
AI:您可以使用以下代码来获取指定命名空间下所有的Service信息:
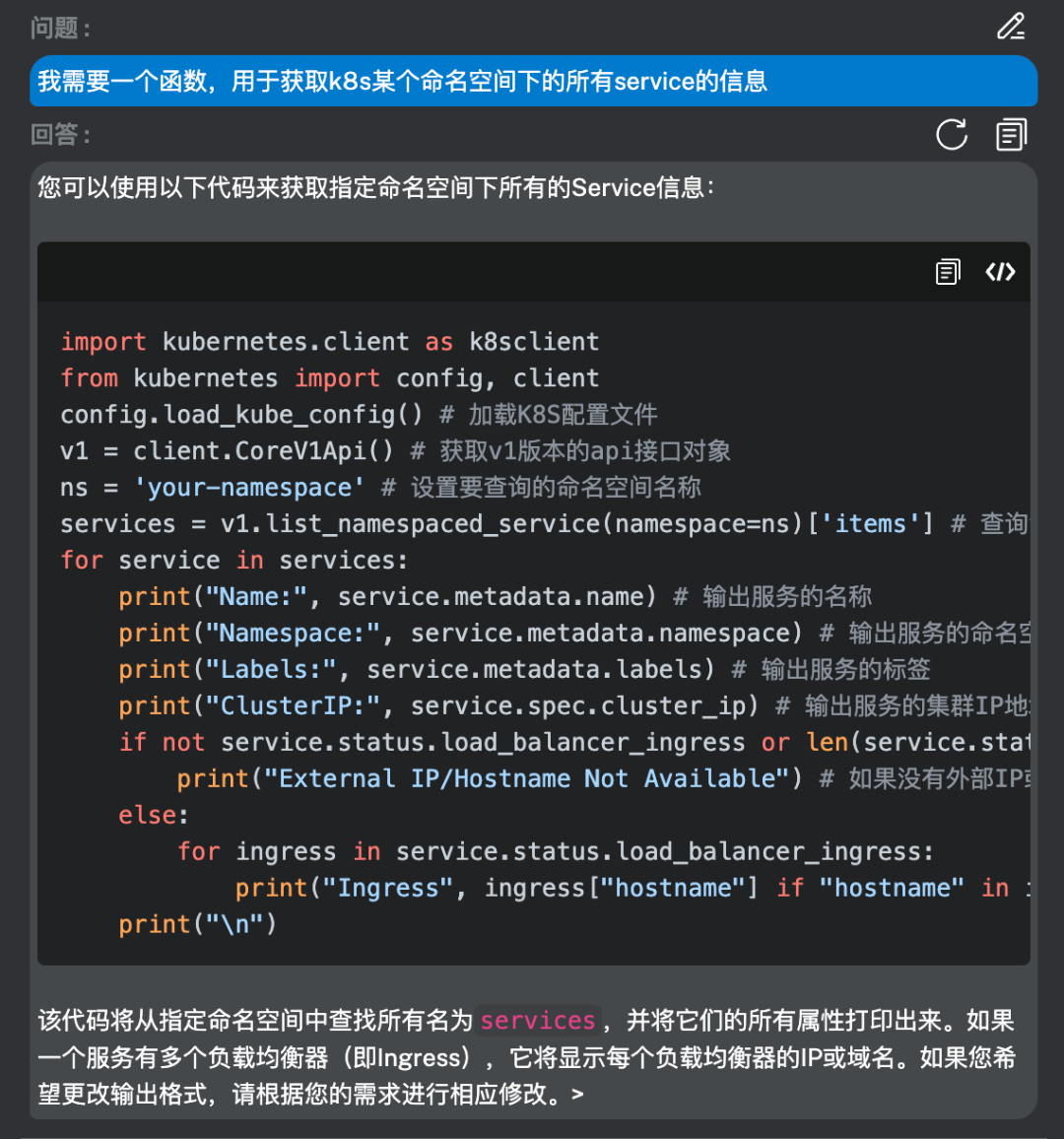
利用模型生成代码,非常方便
对话生成页面
在开发一个新的页面时,我需要根据产品经理提供的页面布局和功能需求,编写相应的代码。通过与博云研发大模型进行对话,我描述了页面的结构、元素和样式,随后大模型生成了对应的代码,使我能够快速开始页面的开发工作。
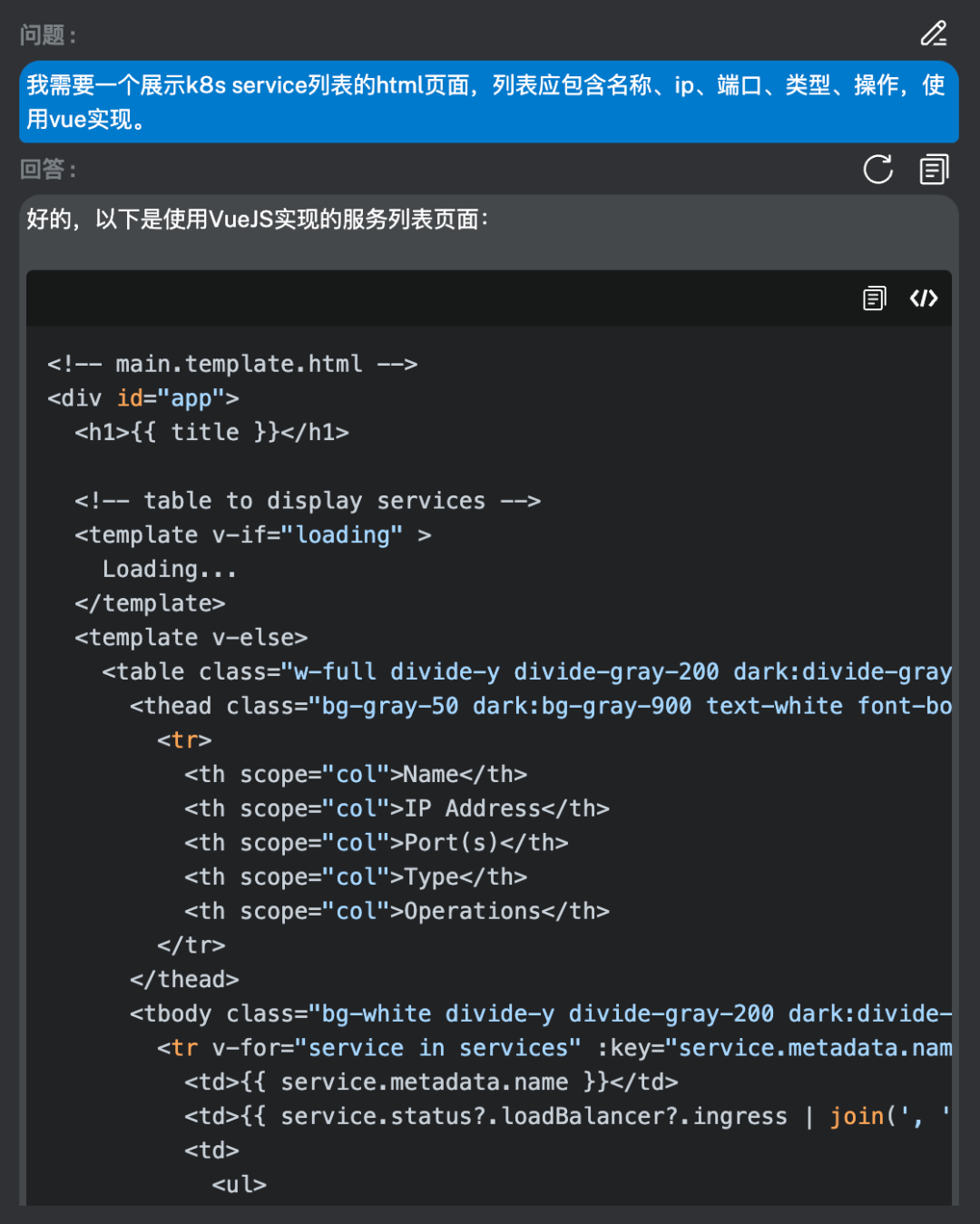
Q:我需要一个展示k8s service列表的html页面,列表应包含名称、ip、端口、类型、操作,使用vue实现。
AI:好的,以下是使用VueJS实现的服务列表页面:
辅助开发
在辅助开发场景中,博云研发大型语言模型提供了多种功能来帮助开发人员提高编码效率和代码质量。
代码续写
在编写一个新功能时,我需要与已有的代码进行交互。通过大型语言模型的功能上下文代码补全,我只需输入部分代码,模型就会根据上下文提示可能的函数名和参数,帮助我快速选择并完成代码。
注释生成代码
当我开始使用大型模型来辅助我的代码编写时,我发现这项技术极大地提高了我的开发效率。我只需简单地描述我想要实现的功能或逻辑,模型就能够为我生成相应的代码片段、函数甚至整个程序。
举个例子,我需要实现一个用于批量获取k8s资源的功能。我向模型描述了这个函数应该做的事情。然后,模型就会智能地分析已有的代码片段和上下文,为我提供准确的建议。
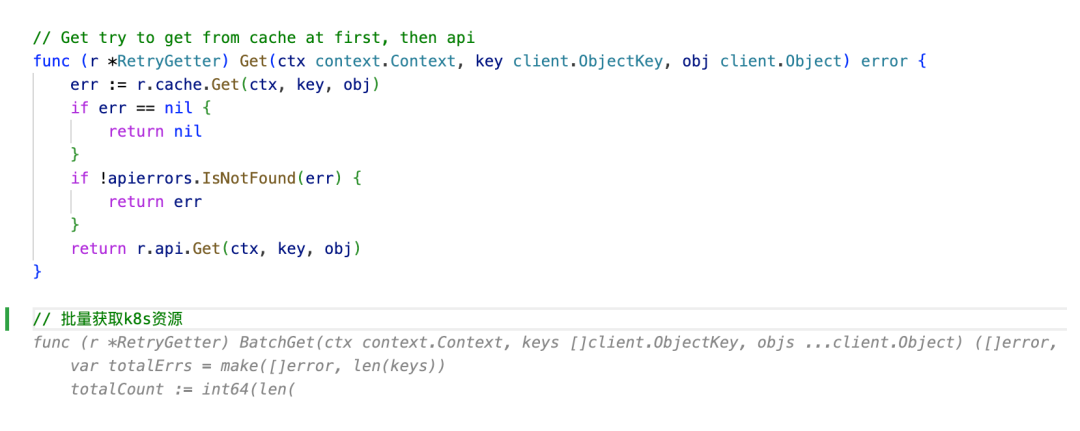
代码优化
在日常开发中,经常会遇到需要优化代码以提高性能或者可读性的情况。有时候,我可能会写出冗长或者低效的代码,但是我知道通过优化可以使代码更加简洁、高效。
举例来说,假设我有一个函数来计算列表中所有数字的总和:
```
numbers = [1, 2, 3, 4, 5]
total = 0
for num in numbers:
total += num
print(total)
```
虽然这段代码能够正确地计算总和,但是我知道可以使用 Python 内置函数 sum() 来更简洁地实现相同的功能:
```
numbers = [1, 2, 3, 4, 5]
total = sum(numbers)
print(total)
```
然而,有时候我可能会忘记或者不确定是否可以使用 sum() 函数来优化代码。在这种情况下,我会使用博云研发大模型来帮助我检查和改进代码。
我可以将这段代码输入到博云研发大模型的界面中,并触发代码优化功能。大模型会分析我的代码并提供改进建议。例如,它可能会建议我使用 sum() 函数来简化代码:
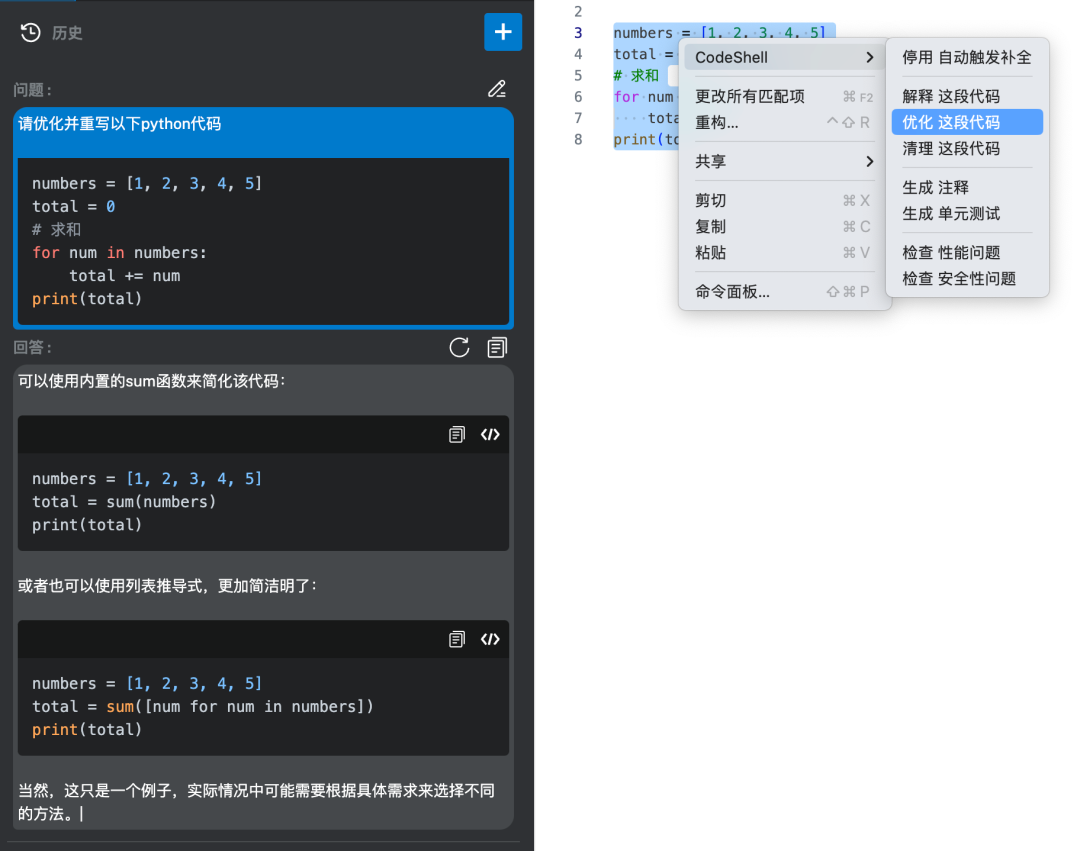
清理代码
在日常开发中,有时候可能会遇到需要清理代码以提高可读性和可维护性的情况。一个常见的场景是在处理数据时,可能会产生大量的重复代码或者不必要的复杂性。
举例来说,假设我正在开发一个文本编辑的页面,其中一个功能是统计文本中各个单词出现的次数。初始版本的代码可能会是这样的:
```
def count_word_occurrences(text):
words = text.split()
word_count = {}
for word in words:
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
return word_count
```
尽管这段代码能够正确地统计文本中各个单词出现的次数,但是我觉得可以进一步简化或者重构。在这种情况下,我会使用博云研发大模型的代码清理功能来帮助我改进代码。
我可以将这段代码输入到博云研发大模型的界面中,并触发代码清理功能。该功能会分析我的代码并提供改进建议。例如,它可能会建议我使用 Python 的 collections.Counter 类来简化单词计数的过程:
```
import collections
# 统计文本中各个单词出现的次数
def count_word_occurrences(text):
counter = collections.Counter(text.lower().split())
return dict(counter)
```
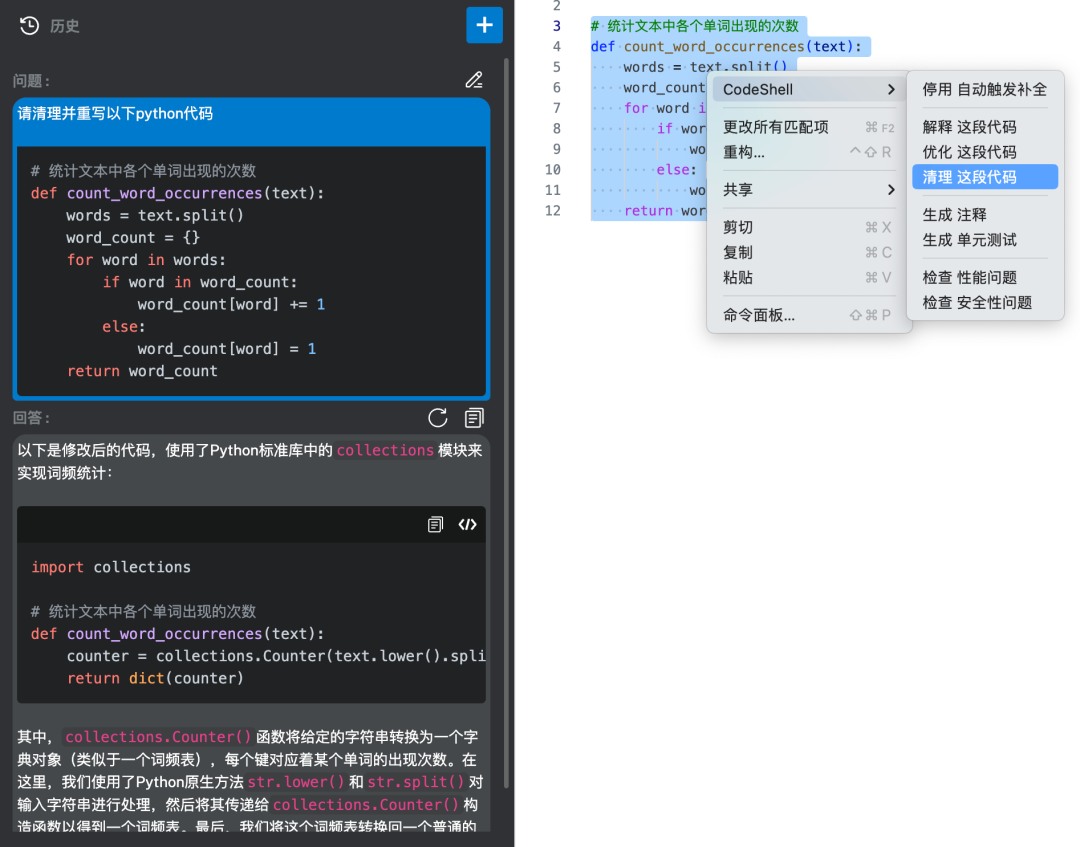
生成注释
在日常开发中,有时候我会遇到需要为复杂算法或者数据结构添加注释的情况。尽管我知道好的注释可以提高代码的可读性和可维护性,但是有时候我可能会因为代码复杂或者理解困难而忽略这一步骤。
举例来说,假设我正在编写一个函数来实现快速排序算法,该算法用于对一个列表进行排序。初始时,函数可能是这样的:
```
def quick_sort(arr):
"""
快速排序算法的实现。
参数:
- arr: 待排序的列表
返回值:
排序后的列表
"""
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
```
尽管函数的功能很明确,但是快速排序算法可能对于某些开发者来说不是很熟悉,因此注释可能需要更详细的解释。在这种情况下,我会使用博云研发大模型的生成注释功能来帮助我完善注释。
我将函数的定义输入到博云研发大模型的界面中,并触发生成注释功能。该功能会分析函数的参数和功能,并为我生成一个更详细的注释模板,如下所示:
```
def quick_sort(arr):
"""
快速排序算法的实现。
这个函数用于对传入的数组进行排序。它采用分治策略,通过选择一个元素作为枢轴点,将小于枢轴点的元素放到左边,大于枢轴点的元素放到右边,然后再分别对左右子序列进行递归调用,直到整个数组有序为止。
:param arr: 要排序的数组
:type arr: list
:return: 排序后的数组
:rtype: list
"""
# 如果长度小于等于1则直接返回该数组
if len(arr) <= 1:
return arr
# 从数组中间取出一个元素作为枢轴点
pivot = arr[len(arr) // 2]
# 将所有比枢轴点小的元素放在左边,大的放右边
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
# 对左边的部分进行递归调用
sorted_left = quick_sort(left)
# 把已经排好序的中间部分放入结果数组
result = []
result.extend(sorted_left)
result.extend(middle)
# 对右边的部分进行递归调用
sorted_right = quick_sort(right)
# 把已经排好序的右边部分放入结果数组
result.extend(sorted_right)
# 返回最终的结果数组
return result
```
测试用例
在测试用例场景中,博云研发大模型可以根据给定的代码段自动生成相应的单元测试,帮助开发人员验证代码的正确性和健壮性,从而提高代码的质量和稳定性。
单元测试
假设我编写了一个函数来实现快速排序算法,现在我想要编写相应的单元测试,以确保函数的正确性。就可以使用博云研发大模型为我快速生成相应的测试用例。
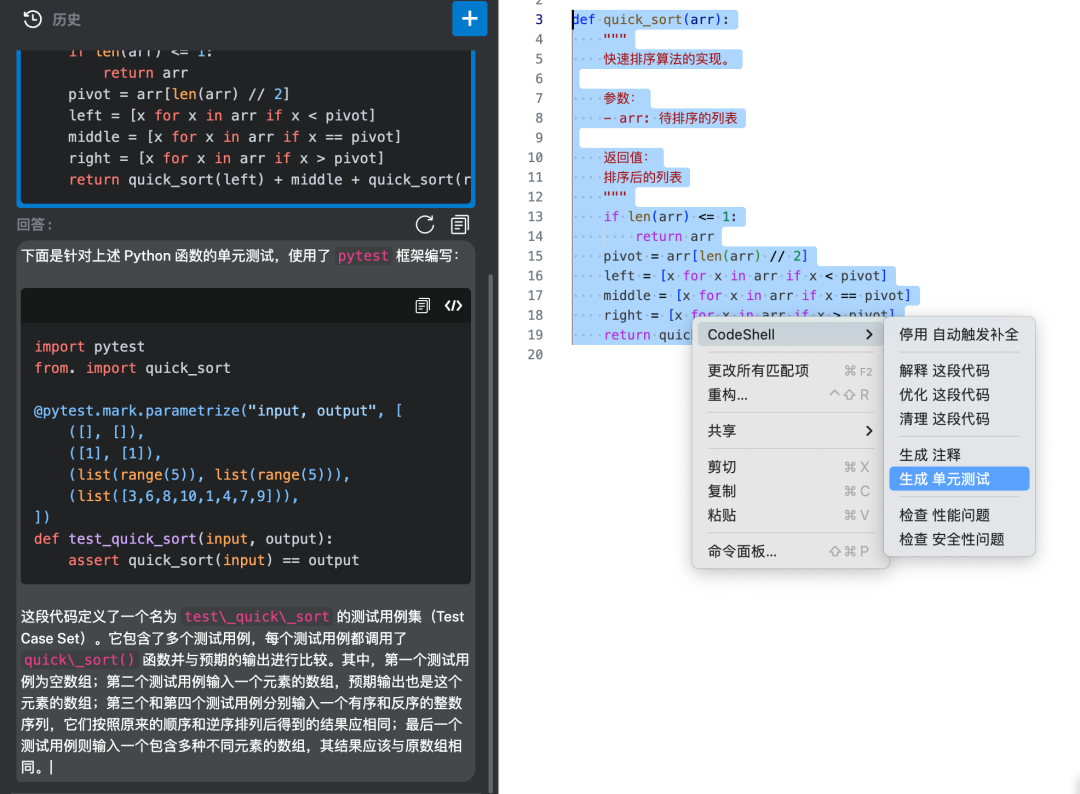
(模型根据函数签名和逻辑自动生成了相应的单元测试代码)
代码检查
博云研发大模型可以检查代码中的性能问题和安全性问题,帮助开发人员及时发现并解决潜在的性能瓶颈和安全隐患,保障软件系统的稳定性和安全性。
性能检查
在日常开发中,有时我们需要进行数据库的批量查询或修改操作,比如批量获取用户信息、批量更新状态等。在这种情况下,我们需要确保代码的效率和安全性。让我描述一个相关的场景:
假设我们的系统需要根据一组用户ID批量查询用户信息,并将他们的邮箱地址修改为新的值。我们的数据库中有一个名为users的表,包含了用户的ID、用户名和邮箱地址等信息。我们需要写一个函数来实现这个功能。
```
# 批量查询和修改用户邮箱地址函数
def batch_update_email(user_ids, new_email):
# 构造 SQL 查询
query = "UPDATE users SET email='%s' WHERE user_id IN (%s)" % (new_email, ",".join(map(str, user_ids)))
# 执行更新
execute_query(query)
# 调用批量查询和修改用户邮箱地址函数
user_ids = [1, 2, 3, 4, 5]
new_email = "new_email@example.com"
batch_update_email(user_ids, new_email)
```
大模型给出的建议:
使用占位符替换字符串拼接:将查询改为使用占位符,如 WHERE user_id IN (%s)。
将列表转换为 Pandas DataFrame:如果需要处理大规模数据并进行多次查询或操作,可以将其转换为 Pandas DataFrame。
对 SQL 查询进行预编译:使用 PyMySQL 模块或者其他类似的数据库连接模块时,可以对 SQL 查询进行预编译以提高性能。
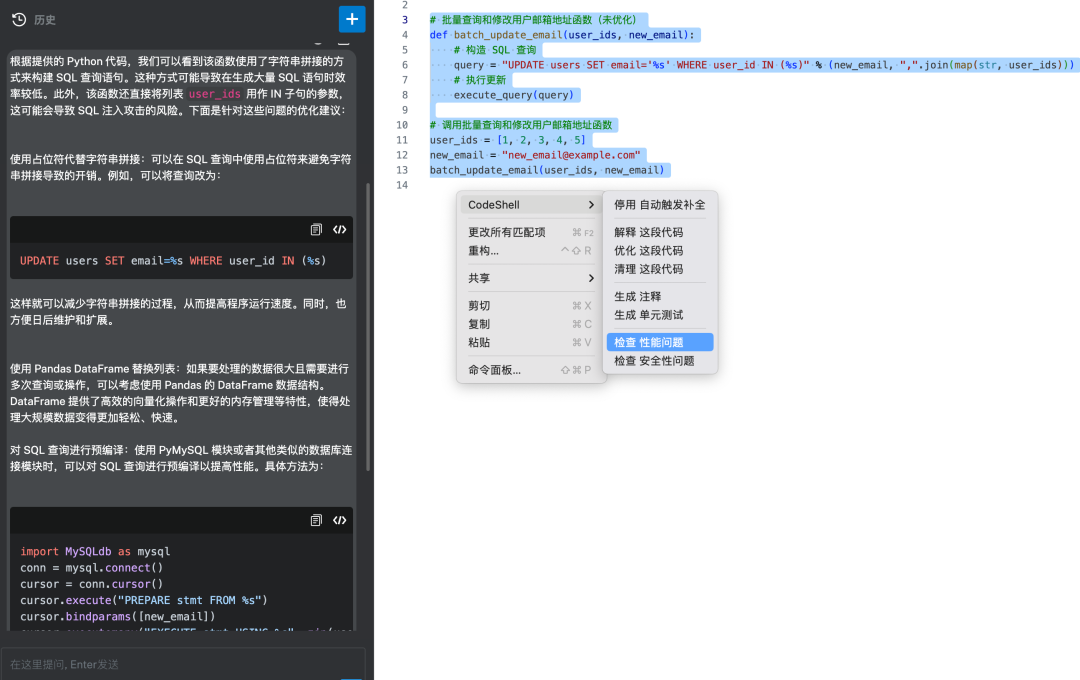
安全性检查
在用户登录功能中,我们需要防范 SQL 注入攻击,因为这是一个常见且危险的安全漏洞。
假设我们有一个用户登录页面,用户需要输入用户名和密码来登录系统。我们的系统使用了一个后端数据库来存储用户信息,包括他们的用户名和密码。登录功能的代码可能类似于下面这样:
```
# 用户登录函数
def user_login(username, password):
# 构造 SQL 查询
query = "SELECT * FROM users WHERE username='%s' AND password='%s'" % (username, password)
# 执行查询
result = execute_query(query)
# 检查是否有匹配的用户
if result:
return "登录成功,欢迎回来,%s!" % username
else:
return "登录失败,请检查用户名和密码。"
```
在这个例子中,我们构造了一个 SQL 查询字符串,将用户输入的用户名和密码直接拼接到查询字符串中。这种做法非常危险,因为恶意用户可以利用输入特殊字符来执行恶意的 SQL 代码,从而绕过身份验证并获取敏感数据,这就是 SQL 注入攻击的原理。
为了防范 SQL 注入攻击,我们可以采用参数化查询的方式,而不是直接将用户输入拼接到 SQL 查询字符串中。大模型修改后的代码如下:
```
import re
def login_check(params):
try:
username, password = map(str.title for a, b in params["form"].items())
pattern = r"(^\w+)$"
if not re.match(pattern, username):
raise ValueError("Invalid username format.")
db = connect_to_database()
c = db.cursor()
query = "SELECT * FROM users WHERE username=? and password=?"
data = (username, password)
c.execute(query, data)
results = c.fetchall()
if results:
message = "Login success!"
c.close()
db.close()
return render_template("index.html", message=message)
else:
message = "Incorrect username or password."
error_message = {"error": message}
db.close()
return render_template("index.html", **error_message)
except Exception as err:
db.close()
return jsonify({"result": False, "reason": str(err)})
```
这样,即使用户输入了特殊字符,参数化查询也会对其进行转义处理,从而有效地防止了 SQL 注入攻击,保障了用户登录功能的安全性。

综上所述,大语言模型在代码辅助开发中的实践为开发人员提供了强大的工具和支持,极大地提高了软件开发的效率和质量。随着技术的不断进步和模型的不断优化,相信大语言模型将在未来发挥越来越重要的作用,为软件开发领域带来更多的创新和突破。
博云AIOS
AIOS是博云专为AI应用推出的企业级一站式人工智能操作系统,屏蔽底层异构算力差异,面向大规模分布式计算,在计算、网络、存储、调度等基础能力全面增强,为AI应用提供稳定、高效、极简的底层支撑能力。同时AIOS支持主流的分布式AI深度学习框架,可满足算法、模型、组件的可视化开发,覆盖算法开发、数据管理、模型训练、在线推理的全生命周期。AIOS可以帮助企业和开发者自主构建人工智能业务,助力企业保持行业领先能力。
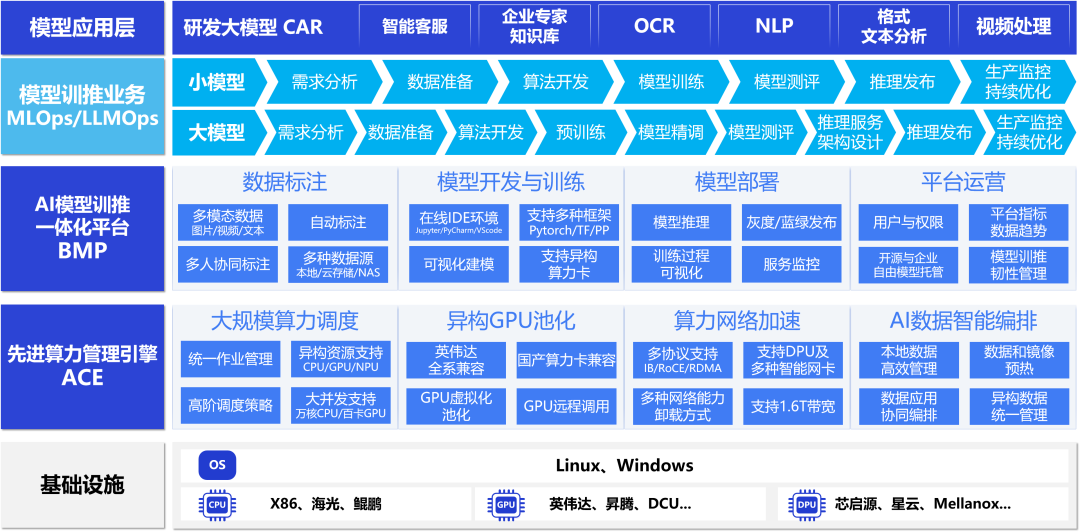
强大的底层掌控能力
AIOS的核心在于其强大的BKE-Turbo算力引擎,支持高达5000个节点的稳定调度,以及异构GPU池化管理,确保了多租户算力的强隔离和全方位监控。
功能特性
覆盖深度学习业务全流程,加快模型从研发到上线速度。
深度学习训练任务通常包含多个阶段,从数据处理、算法开发、模型训练、超参调整、模型管理与部署等,AIOS提供全流程支持。
快速部署计算环境并启动训练任务,提高研发效率
深度学习框架和模型众多,依赖各不相同,对开发环境的要求比较复杂, AIOS可以实现资源和工作环境的隔离及快速部署。
支持数据集统一管理,提升数据标注效率
数据集种类众多,数据标注工具不一。AIOS内置多种数据集标注工具,支持人工标注、协同标注、智能标注等多种业务场景,极大提升数据标注效率。
支持多种建模方式,方便算法工程师快速构建复杂模型
支持Jupyter交互式建模,方便算法工程师对代码进行调试;平台内置多种算法组件,支持通过拖拉拽方式实现可视化建模,极大降低建模门槛。
训练过程可视化,掌握训练进度及质量
深度学习模型训练周期较长,训练结束后才发现模型质量问题。借助AIOS,可以实现对训练过程实时监控并可视化训练过程,实时观测损失函数值的日志、训练误差或测试误差等。
动态分配 GPU 资源,充分利用资源,提高资源利用率
支持 GPU 资源细颗粒度调度能力,最低可划分1%资源。同时支持众多国产GPU算力。单一计算集群可以统一管理异构的多种GPU算力。
全面的集群监控管理,实时掌握 CPU/GPU 资源使用情况及运行状态
实时监控集群的使用情况,合理安排训练任务;及时发现运行中的问题,提高集群的可靠性。

方案优势概览



