
“GPU分区”和“GPU池化”是高性能计算领域中,管理和优化GPU资源使用的概念和技术。它们都旨在提高GPU资源的利用率和灵活性,但侧重点有所不同。
GPU分区
定义:
GPU分区指的是将单个GPU的资源(如计算能力、内存等)划分成多个独立的部分,每部分可以被不同的任务或用户独立使用。这种技术可以让多个进程同时共享单个GPU,而不会互相干扰。
目的:
GPU分区主要用于提高GPU的利用率,尤其是在单个任务无法完全利用GPU全部资源的情况下。通过分区,多个较小的任务可以同时运行在一个GPU上,从而减少资源浪费。
实现方式:
可以通过硬件支持实现,例如某些GPU提供了硬件级的虚拟化功能,也可以通过软件在更高层次上模拟分区效果。
GPU池化
定义:
GPU池化是指将多个GPU资源集中管理,形成一个资源池,根据需要动态分配给不同的计算任务。这种方法可以跨物理机、集群甚至数据中心,整合多个GPU资源。
目的:
GPU池化旨在提高资源分配的灵活性和效率,尤其适用于需要大量GPU资源的大规模计算任务。通过池化,系统可以根据任务需求动态调整GPU资源的分配,优化资源使用。
实现方式:
GPU池化通常依赖于特定的资源管理器或调度软件,如Kubernetes中的GPU资源调度、NVIDIA的DGX系统等,它们能够管理资源分配,监控GPU使用状态,并根据需求动态调整资源分配策略。
池化是容器厂商擅长做的事
总的来说,GPU分区是关于单个GPU资源的内部划分和共享,而GPU池化关注的是多个GPU资源的集中管理和动态分配。两者都是现代高性能计算环境中,提高GPU利用率和计算效率的重要技术。
可以简单粗暴地理解为:GPU是GPU硬件厂商常做的事,而池化是容器厂商梗擅长做的事。
比如NVIDIA通过其虚拟GPU(vGPU)技术提供硬件级别的GPU分区,允许单个GPU资源被虚拟化并分配给多个虚拟机或容器。这种分区技术使得每个用户或任务都感觉像是拥有一个独立的GPU,而实际上是共享同一个物理GPU的资源。
GPU分区 VS GPU池化
硬件厂商的虚拟化功能
优点
性能接近原生:
硬件级的虚拟化功能,如GPU分区,通常能提供更接近原生硬件性能的体验,因为它们减少了软件层面的开销。
安全隔离:
硬件支持的虚拟化可以提供较强的安全隔离性,因为它在更低的系统层面上分隔资源。
缺点
兼容性和灵活性:
硬件厂商的虚拟化方案出于商业化角度考虑,可能在兼容性和灵活性方面受限,特别是在跨多种硬件平台和环境部署时。即,如果有多品牌硬件的基础环境,需要慎重考虑。
成本:
依赖特定硬件的虚拟化功能可能会涉及更高的成本,不仅仅是硬件购买成本,还包括必要的许可费用。一个字,贵!很贵!
容器池化方案
优点
跨平台和高度灵活性:
容器技术(如Docker)和容器编排工具(如Kubernetes)支持跨不同环境和平台的部署,提供高度的灵活性和可移植性。
资源利用率和扩展性:
容器池化方案能够有效地提高资源利用率,方便地进行水平扩展,以适应不同的负载需求。
成本效益:
容器技术可以在不依赖特定硬件的情况下实现资源的有效管理和调度,有助于降低总体成本。
缺点
性能开销:
虽然现代容器技术的性能开销已经相当小,但在一些性能敏感的应用场景中,容器化的应用仍然可能无法完全达到原生硬件性能。
安全性:
虽然容器技术不断进步,在安全性方面取得了很大进展,但在某些情况下,容器间的隔离可能不如硬件级虚拟化那样严格。
客户该如何选择?
在选择硬件厂商的虚拟化功能还是容器池化方案时,客户需要考虑以下几个方面:
性能需求:
如果应用对性能有极高的要求,特别是需要接近原生硬件性能,可能更倾向于选择硬件虚拟化方案。如,博云自研GPU分片方案是基于CUDA层软件切分实现,多种AI工作负载下实测性能损耗不超过5%。
成本预算:考虑总体成本,包括硬件、软件许可、运维等费用,容器池化方案成本效益更高。
部署环境和兼容性:
如果需要跨多种环境和平台部署,容器池化方案可提供更大的灵活性和兼容性。
扩展性和资源管理:
对于需要动态扩展的场景,容器池化方案可能更为合适,因为它支持更灵活的资源管理和调度。
在对话的最后


相关产品介绍
AIOS是博云专为AI应用推出的企业级一站式人工智能操作系统,屏蔽底层异构算力差异,面向大规模分布式计算,在计算、网络、存储、调度等基础能力全面增强,为AI应用提供稳定、高效、极简的底层支撑能力。同时AIOS支持主流的分布式AI深度学习框架,可满足算法、模型、组件的可视化开发,覆盖算法开发、数据管理、模型训练、在线推理的全生命周期。AIOS可以帮助企业和开发者自主构建人工智能业务,助力企业保持行业领先能力。
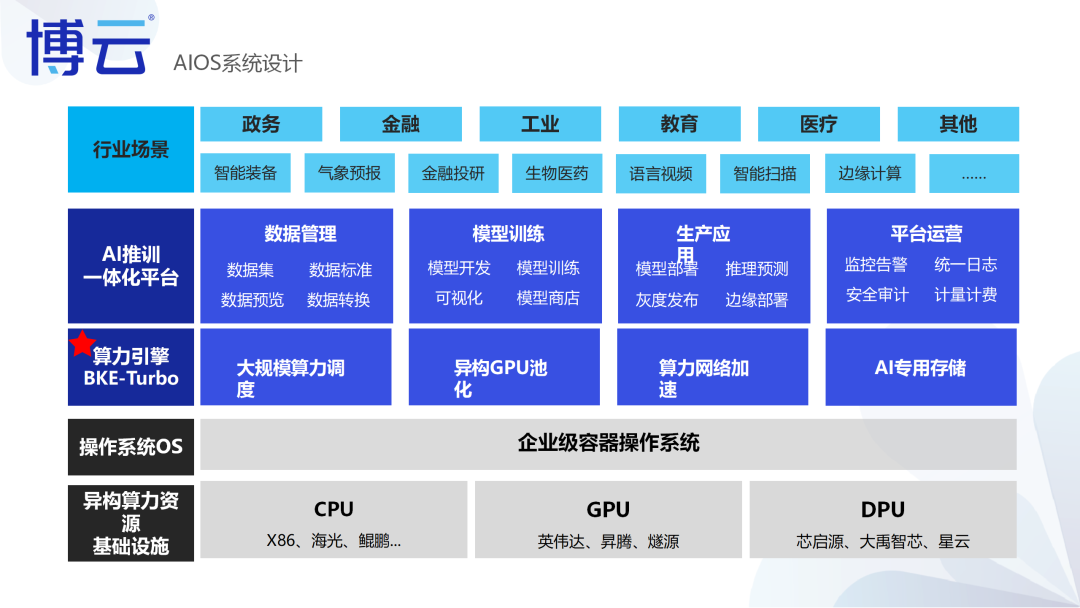
强大的底层掌控能力
AIOS的核心在于其强大的BKE-Turbo算力引擎,支持高达5000个节点的稳定调度,以及异构GPU池化管理,确保了多租户算力的强隔离和全方位监控。
功能特性
覆盖深度学习业务全流程,加快模型从研发到上线速度。
深度学习训练任务通常包含多个阶段,从数据处理、算法开发、模型训练、超参调整、模型管理与部署等,AIOS提供全流程支持。
快速部署计算环境并启动训练任务,提高研发效率
深度学习框架和模型众多,依赖各不相同,对开发环境的要求比较复杂, AIOS可以实现资源和工作环境的隔离及快速部署。
支持数据集统一管理,提升数据标注效率
数据集种类众多,数据标注工具不一。AIOS内置多种数据集标注工具,支持人工标注、协同标注、智能标注等多种业务场景,极大提升数据标注效率。
支持多种建模方式,方便算法工程师快速构建复杂模型
支持Jupyter交互式建模,方便算法工程师对代码进行调试;平台内置多种算法组件,支持通过拖拉拽方式实现可视化建模,极大降低建模门槛。
训练过程可视化,掌握训练进度及质量
深度学习模型训练周期较长,训练结束后才发现模型质量问题。借助AIOS,可以实现对训练过程实时监控并可视化训练过程,实时观测损失函数值的日志、训练误差或测试误差等。
动态分配 GPU 资源,充分利用资源,提高资源利用率
支持 GPU 资源细颗粒度调度能力,最低可划分1%资源。同时支持众多国产GPU算力。单一计算集群可以统一管理异构的多种GPU算力。
全面的集群监控管理,实时掌握 CPU/GPU 资源使用情况及运行状态
实时监控集群的使用情况,合理安排训练任务;及时发现运行中的问题,提高集群的可靠性。

方案优势概览



