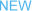

博云PaaS产品线平台架构师梁兵受邀参加5月28日Cloud Native Summit分论坛活动,联合华为Volcano社区member汪洋,共话《一种基于云原生批量计算平台Volcano的工作流编排引擎JobFlow》主题分享。
以下根据演讲内容整理。
关键词:大规模、高性能、批量计算
分享人:
汪洋 | 华为云高级软件工程师, Volcano社区成员
梁兵 | 博云PaaS产品线平台架构师
关于Volcano和JobFlow
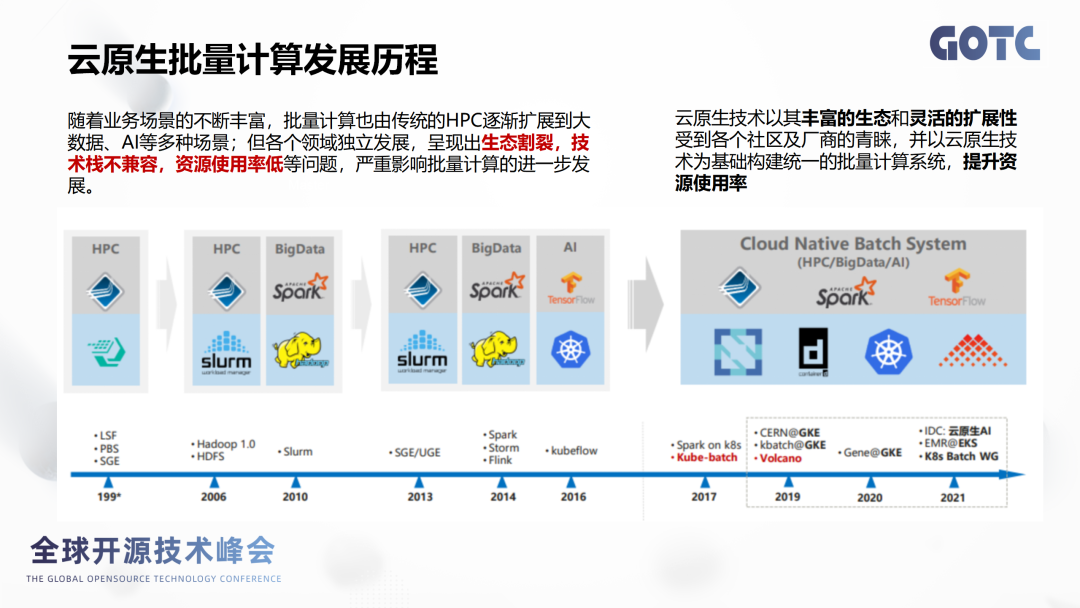
Volcano是华为云主导开源的面向高性能计算的云原生批量计算平台,寄寓助力企业算力像火山一样爆发。Volcano是CNCF首个云原生批量计算项目,主要特性有统一的作业管理、丰富的高阶调度策略、细粒度的资源管理、性能优化和异构资源管理。
JobFlow为Volcano社区孵化中的子项目,由博云主导并联合社区开发者共同贡献,是一种轻量化任务流编排引擎,帮助用户简洁化管理多个任务的并行与依赖关系,大幅度提升整体计算效率,可广泛应用于高性能计算、AI、生物医药、图片处理、美颜、游戏AGI、科学计算等场景。JobFlow已在国内某知名研究所落地应用,通过任务流编排解决用户数据预热、回收、业务资源限制、过高IO导致节点宕机等问题,在硬件环境不变的前提下,持续提升任务计算效率。
Volcano在工作流编排下的主要挑战
Vocalno产生背景
云原生批量计算生态隔离、技术栈不兼容,无法满足对资源利用率的更高要求。
从云原生批量计算的发展历程来看,批量计算伴随着业务不断发展,由传统的HPC逐渐扩大到大数据的AI场景,包括最初的slurm到基于Hadoop的大数据生态再到云原生的AI生态,三种生态它是独立发展、生态割裂的,技术栈也存在不兼容的问题,影响集群的整体资源利用率。
云原生批量计算所面临的挑战

K8s是以Pod为级别为单位进行调度的,对于大数据和AI上层应用的感知比较弱;
缺乏对于job概念和完善的生命周期管理,如任务依赖、作业依赖的支持度,这一点对于应用来讲存在一定偏差。
调度和性能方面:
缺少vcjob为单位的调度策略,包括vcjob排序、公平调度,包括我们家大数据比较关注常用的场景。
无法满足高级调度策略,如任务拓扑,还有感知回填等。
在性能上,batch的频繁调度业务跟微服务还有一些差别。
领域框架支持方面:
在一个平台里面特别是AI训练大数据的时候,支撑框架非常多,包括MPI、Tensorflow等等,如果1:1 operator部署对运维人员来讲就非常具备挑战性。
其他原因:
关于这种资源共享、异构计算,缺少作业队列的概念,多租户下场景下的资源公平高效复用,也是无法满足我们的要求。
Vocalno特性
统一的作业管理
有一个 vcjob的概念,可以提供完善的作业生命周期管理,支持几乎所有主流计算框架,包括我们提到的这Pytorch、MPI、Horvod、Tesnsorflow、Spark都会支持管理。提供丰富的管理调度策略
比如常用的公平调度、任务拓扑、SLA调度、作业抢占、回填、弹性调度、混部等等。
对细粒度的资源管理
通过queue这个定义来提供作业队列,包括队列的资源预留、队列容量管理,然后多租户的动态资源共享的能力。
性能优化和异构资源管理
结合k8s提供扩展性,异构硬件支持X86、ARM、GPU、昇腾、昆仑等等。
Volcano在工作流编排场景下的主要挑战
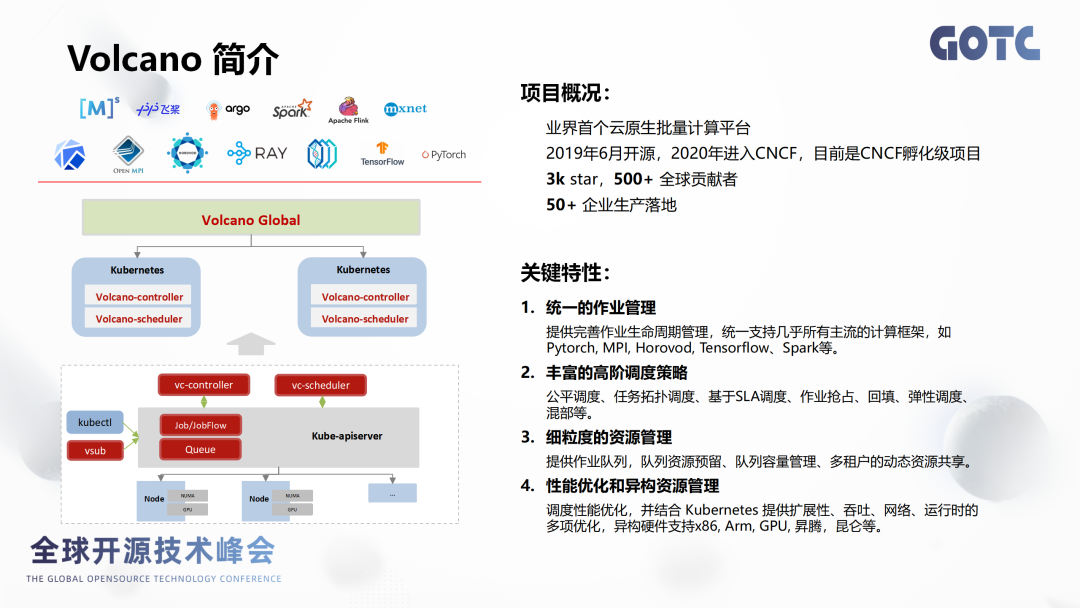
工作流编排的现状
先运行JobA然后运行JobB,之后可以并行运行JobC和JobD,C、D都运行完成之后,我才运行JobE。那么对于这种工作流编排,虽然现在可以完成作业之间的编排,但是目前对这种流式的处理其实不是非常的友好,或者说在这方面的能力是偏弱的。现行处理方式:
1. 人工手动提交多个作业,任务A提交完成之后,再提任务B...这种方式可以解决问题,但是操作太繁琐,重复操作也太多,时间成本较高。
2. 结合公司自研相关的作业平台开发,但这个成本就相对很高了。
3. 结合Argo Wokflow进行完成,但弊端有:
①对vcjob编排,用户可能会依赖running状态,或者是探针的一个形式,workflow通用情况的作业编排将不太适用。
②workflow无法反应vcjob下Pod的状态与对应状态信息。
③Argo Workflow相对来说还是比较通用比较重的,资源占用和维护工作量较大。
JobFlow的设计思想与应用场景
JobFlow产生背景
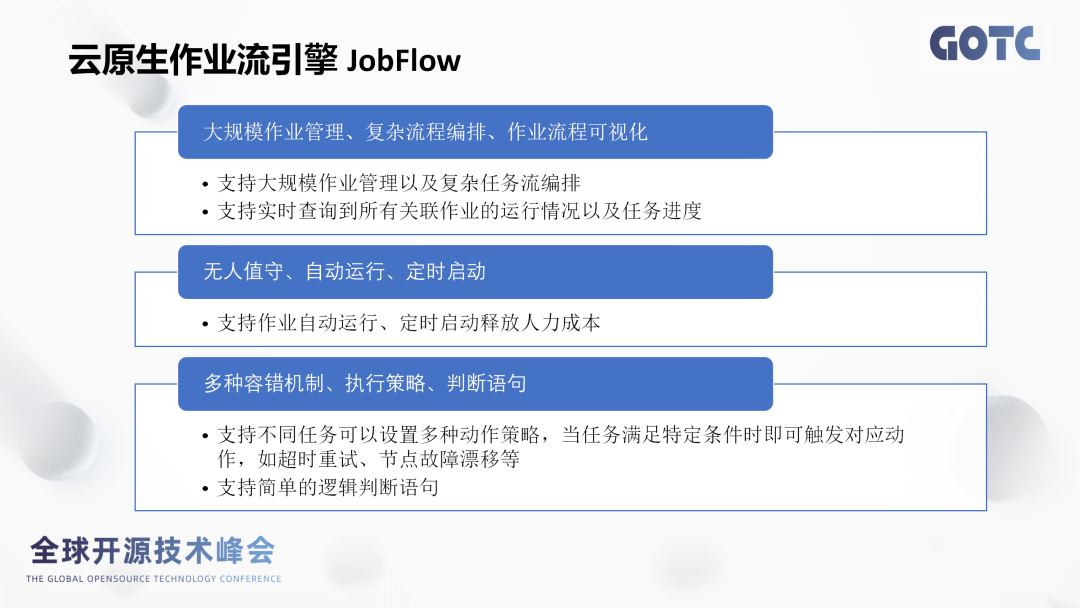
- 用于大规模、复杂的作业编排运行,如大规模作业管理、复杂的流程编排、作业流程可视化等常见场景。
- 通过JobFlow可以实现无人值守、自动运行、还有定时启动这些高级的特性,可以节省开发工程师更多的时间和精力。比如无人值守功能,我们可以下发一个AI的训练作业,然后到对应的时间节点,再上去看一下这个作业情况就可以了。
- JobFlow提供多种容错机制,当节点发生故障的时候,我们可以把这个作业迁移到另外一个节点,保证它的稳定运行。JobFlow它还提供了多种执行策略,比如说条件判断、onSuccess、onFailed以及串行并行处理逻辑等。
JobFlow可以干什么

博云在AI作业训练这一块投入了很多,有很多的客户的作业属于分布式、大规模的作业,动辄就是几千个核心,上万个核心,通过volcano、jobflow可以实现作业的稳定运行。
如一些AI智能计算的场景,像数据集处理、作业的训练、还有模型预测以及最后的推理服务的部署,其实每一个阶段都是一个大的作业,我们把这些作业融合在一起,就形成一个完整的工作流,然后实现一键上线与下线这样一个能力。
再比如一些科研的院校和军工的单位,之前作业是直接跑在物理机上,大概有几百个节点的规模,但资源利用率是比较低的,后面引入volcano调度和JobFlow作业编排能力,现在资源利用率基本提到90%以上。
JobFlow整体设计
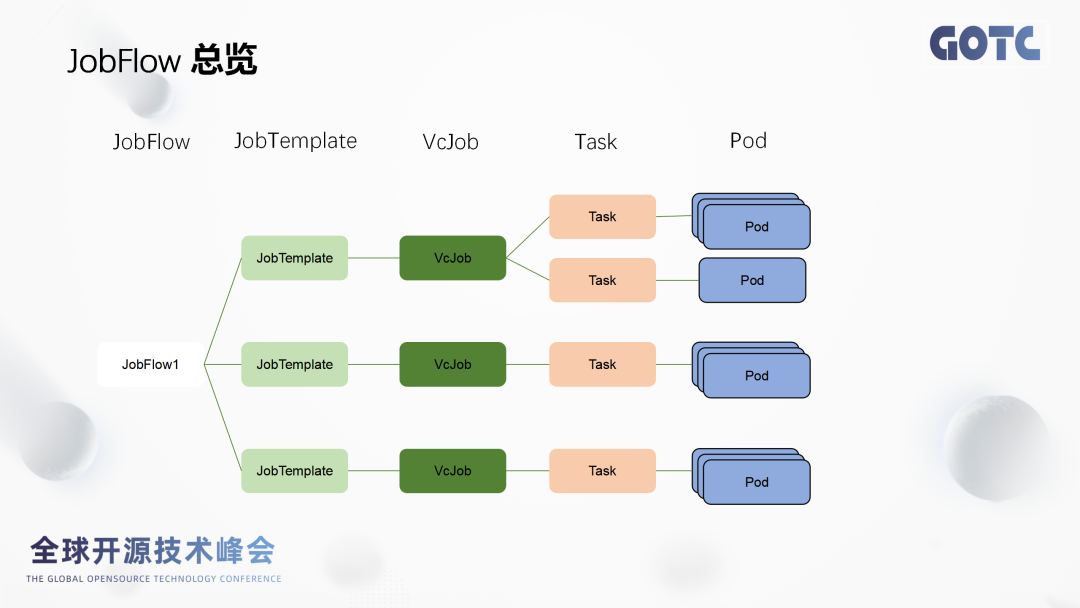
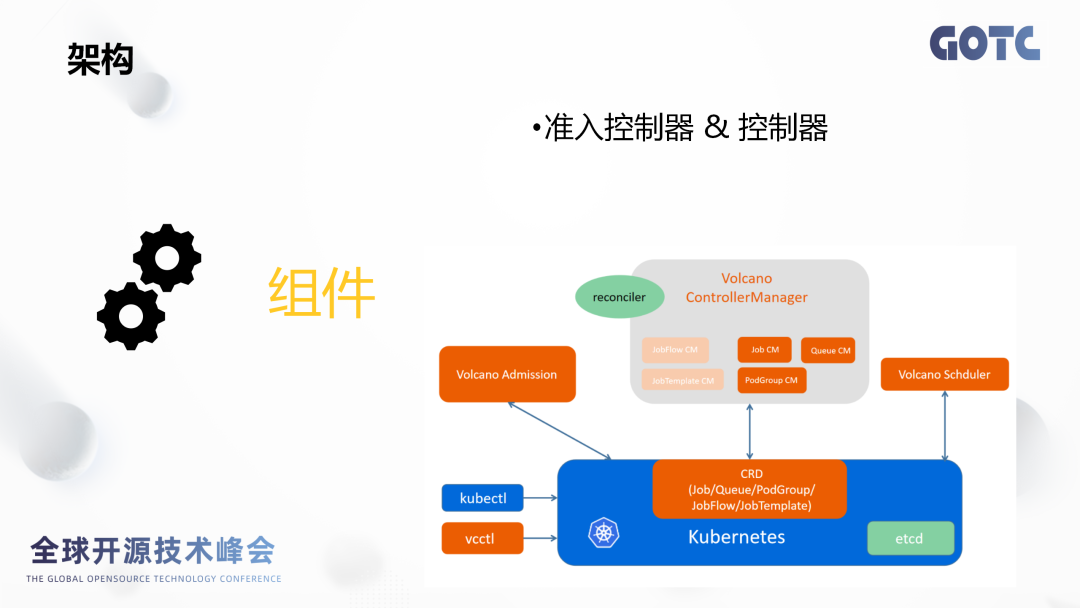

- 鉴权通过之后,将通过kube-API" target="_blank">apiserver创建JobTemplate和JobFlow两个资源对象。
- JobFlowController根据Job Flow的配置以JobTemplate为模板,根据对应的模板任务信息创建对应vcJob。值得注意是JobTemplate是一个可复用的资源,当我们很多的作业模板类似时,我们只需要创建一个JobTemplate。
- Vcjob创建完成之后, Vcjob Controller会去创建对应的Pod和PodGroup。
- Vc-scheduler会从Kube-API" target="_blank">apiserver里获取Pod/PodGroup和节点信息,并将节点信息存到用对应的Vcjob状态里面去。
- 节点分配对应的Pod。
- Kubelet会从Kube-API" target="_blank">apiserver获得配置,启动相应的容器。
后面还可能涉及到job运行完成之后,状态信息的收集、状态信息同步,还有一些钩子函数的触发等操作。
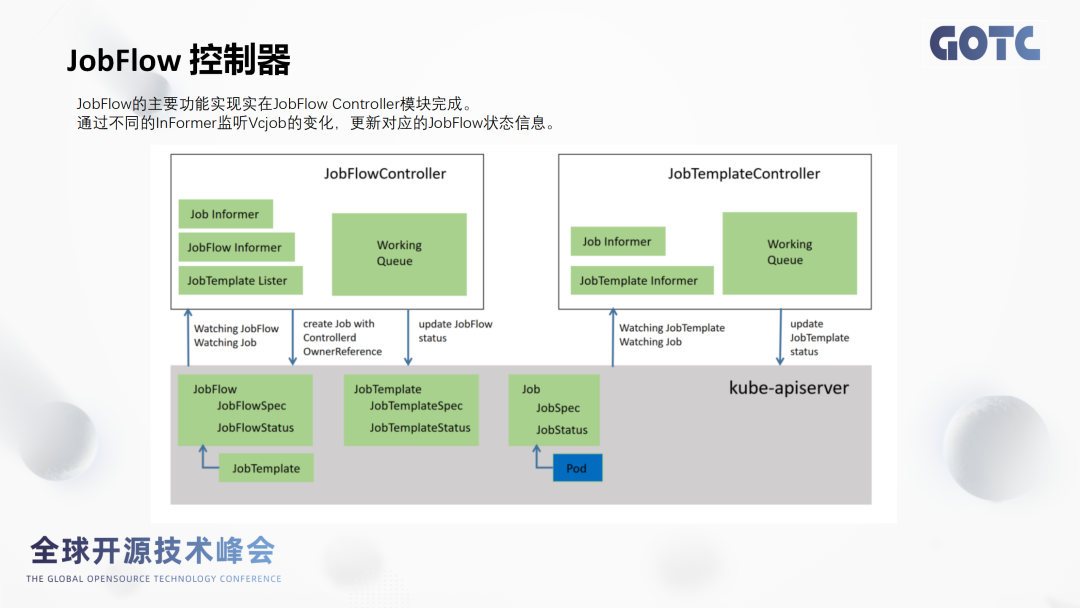
InFormer机制:JobFlow Controller是根据InFormer机制去接收事件信息,然后根据不同事件信息做出一系列的操作以及状态更新。
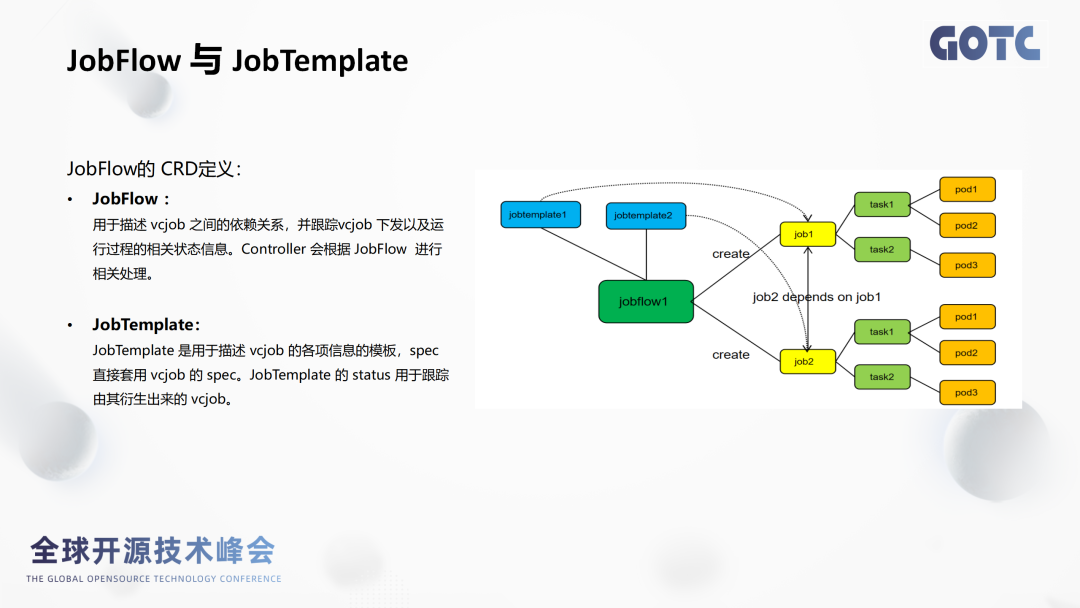
JobFlow描述的是Vcjob跟Vcjob之间的依赖关系。它能根据Vcjob下发的作业跟踪到对应的作业运行情况,然后把对应作业状态信息再存到vcjob的“状态”字段里面去。这个状态信息,可以帮助研发工程师看到整个工作流的运行情况,方便实时判断。
JobTemplate用于描述Vcjob各项信息的模板。这里的Spec字段是直接套用vcjob的spec,其实可以理解JobTemplate就是vcjob的一个套壳,这套壳的意义在于将JobTemplate和vcjob它独立开来,不影响各自的控制逻辑。
JobFlow在生产环境中的应用实践与收益
场景一:AI模型训练推理一体化。
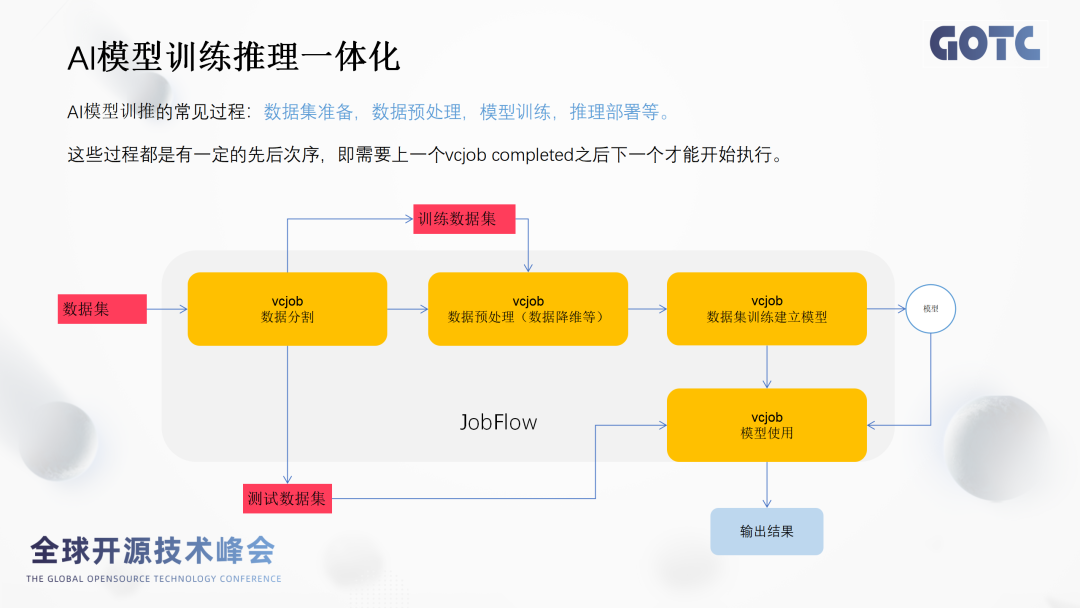
引入JobFlow之后,我们可以把这上面这4个步骤,4个vcjob抽象成1个工作流,然后只需要在执行工作流的yaml文件。执行完之后所有的任务都能按照编排的逻辑创建对应的任务并运行。最终实现一次配置,自动运行的能力,因此开发者只需用极少的精力启动训练作业, 从而能将更多的精力投入到算法开发以及模型调参的过程当中。
场景二:多任务复杂依赖场景。
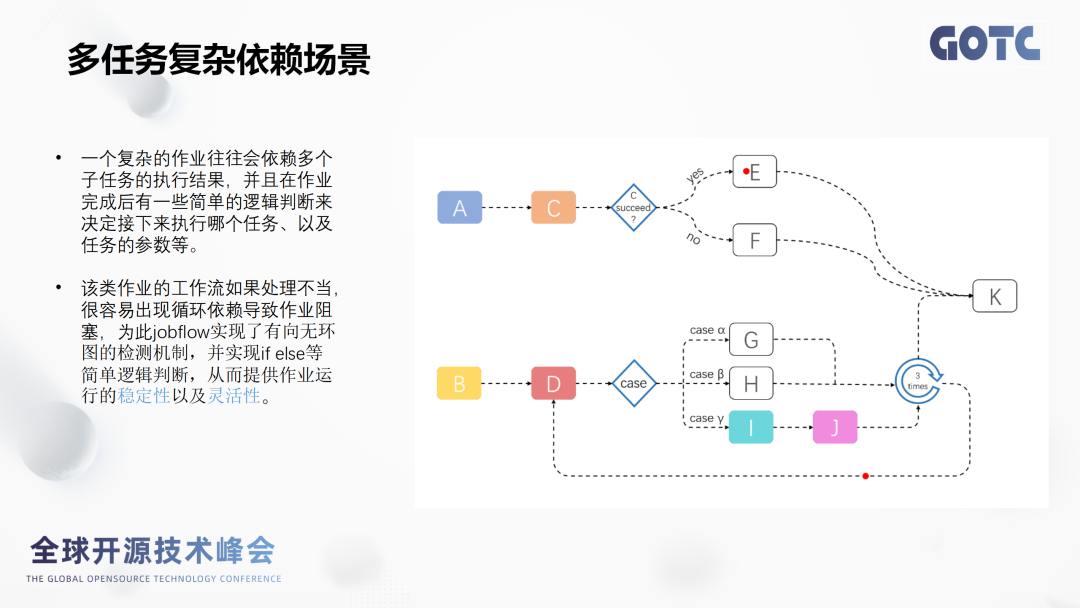
引入JobFlow之后,我们可以根据JobFlow里面提供的dependsOn字段,我们把任务K依赖子任务都配置好,并且设置对应的判断逻辑,最终保证任务的执行顺序跟预想一致。
其他场景

容错机制:通过webhook依赖检测逻辑,能有效规避因操作不当导致任务重复依赖无法正常退出,大量占用系统资源的情况。计算节点宕机时,jobflow接收到对应的事件,然后可以重新将该节点的任务迁移到正常节点运行。
自创立以来,博云积极拥抱开源生态,坚持向开源生态贡献创新技术力量,通过参与开源社区的技术项目,保持与世界前沿 IT 技术的共振。
博云积极参与十余个开源项目贡献,在CNCF社区综合贡献居全球前10%,排名23。
(博云参与贡献的部分开源项目↓)

博云主导的项目
博云主导的FabEdge边缘容器网络和Carina云原生存储开源项目已成为CNCF沙箱级项目,已获得上千名开发者推荐,赋能千行百业客户实现业务创新。
作为项目专家顾问,博云持续与上下游厂商共建开源解决方案,实现与全球开发者的协作创新,推动开源技术在数字化转型中的加速落地。

欢迎开发者扫码申请入群
(备注公司+项目名称)


