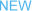

随着互联网的快速发展,我们机房机器数量和种类也是爆炸式的增长,同时运维人员可能每天都要管理成百上千台的机器。面对这么多机器产生的各种各样的监控数据,如果每一条监控数据我们都通过自己写的脚本去处理,不仅工作量大,而且容易出错,想想都可怕。
那有没有好的工具可以直接利用呢?有,它不仅能处理海量监控数据,而且还是一款开源神器。今天我就带大家走进Riemann的世界。
大伙儿在认识Riemann之前,先来看看Rieman是一款什么样的工具。
Riemann 是一个高性能的流事件处理器,它可以接收各种客户端向它推送来的信息,然后把它们放入自己的流处理器中进行处理。Riemann可以对这些数据进行统计、收集、合并、分析等,并可以把处理结果通过短信、电话和邮件发送给指定用户,也可以通过插件转发给RabbitMQ,Elasticsearch, Influxdb等第三方的工具。目前它的最高版本是0.2.12。
作为一款开源的工具,Riemann的设计开发是为了满足大部分人的需求,自然有许多让人满意的功能,也有某些不足。来看看我们的运维小伙伴对于Riemann又有一个什么样的评价。
Riemann的优点
1.高定制化
Riemann的配置文件就是一个Clojure(运行在JVM上的一种lisp方言)程序,它这种配置即程序的方式,及本身提供了丰富的API,这为Riemann提供了一种高伸缩性、高可定制化的可能。它可以对发送来的事件进行收集,统计,整合等各种复杂的应用场景。
2.事件处理低延迟
传统的监控系统都是定时循环处理监控数据,这样难免事件处理有延时。如果是告警信息,过长的延迟发送还可能造成无法挽回的损失。Riemann的处理机制是它只接收客户端推送来的数据,并把数据采用一种流的处理方式,所以数据一旦进入Riemann的流,就会立即获得处理。对于一个商业版的X86机器,Riemann每秒可以处理百万事件,但是却只有毫秒级的延迟。
3.支持多种语言的客户端
Riemann可以接收通过TCP和UDP推送来的数据,这是大部分常用语言所支持的,所以,我们可以很容易的选用一个自己熟悉和喜欢的语言(c++,java,clojure,python等)来写一个自己的客户端去向Riemann发送数据。另外现在也有很多开源的工具已经有自己的插件能去方便的推送自己的数据到Riemann,比如:Collectd,Logstash,JVM,Mysql等。
4.监控数据图形化
它有自己的Dashboard,可以把监控数据图表展示。
5.告警方式多样化
支持与第三工具PaperDuty(一个事件管理平台)整合发送短信和电话告警。也可以通过许多开源的工具,把告警信息发送到Rabbitmq,Elesticsearch, InfluxDB等。
Riemann的缺点
1.必须时间同步
Riemann的数据是按事件传递的,每个事件都有一个自己的时间,如果事件发送方和Riemann时间不同步,并且发送方时间比Riemann时间早,这都有可能造成事件一发送到Riemann它就被标记为过期,从而得不到任何处理。
2.内存消耗大
Riemann处理事件低延迟的原因是,它把所有收到的事件都是放在内存中进行处理的,除了写日志外,它就再也没有其它的磁盘IO操作。Riemann这种处理机制会对内存有很大的消耗。
3.不支持集群
在下面讲高可用的时候,我们会再次讨论到这个问题。
Riemann是怎样工作的
在我们对于Riemann更深入的了解之前,我们必须了解Riemann的几个基本概念,这将是我们进一步学习Riemann的基石,所有Riemann对于监控数据流的处理都是基于这几个概念展开的。
事件(Event)
事件是Riemann的基本的数据结构。Riemann对监控的处理,说白了就是对这些事件的整合、计数、收集、操控、转发等的处理。比如说一台机器的cpu监控,它的一个监控数据发送到Riemann就是一次事件,它的结构形式和我们其它语言中看到的map一样,一个键和值成对出现,我们可以通过这个key去访问事件中的值。在这个事件结构中必须要包含下表中的字段,同时也可以在这些字段的基础上增加一些自己的定制字段。

下面是一个collectd发送给riemann事件的例子:
{:host es_node2, :service df/percent_bytes-total-used, :state remind, :description , :metric 10.043597678752606, :tags [bsm_collectd], :time 1481707384, :ttl 60, :plugin df, :type percent_bytes, :ds_name value, :plugin_instance run, :type_instance total-used, :ds_type gauge, :ds_index 0}
流(Streams)
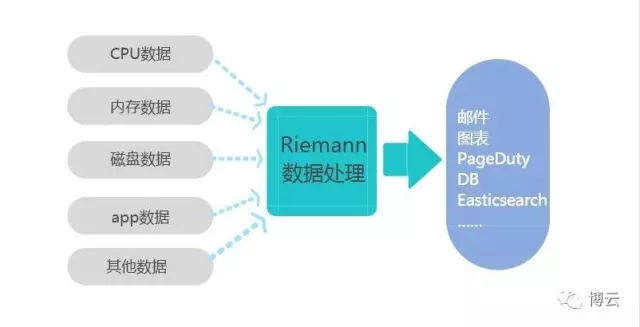
每一个进入riemann的事件都会被增加到一个或多个流中。你能在Riemann配置文件的流代码区域申明你想要的流。你可以配置这个流具有你想要的功能,比如对通过这个流的事件进行收集、计算、修改、过滤等。Riemann也允许你对通过的事件生成新的子流。
Riemann的流你可以想像为现实生活中的管网,而事件就是这个管网中的有着不同性质的液体(事件中不同的host和service)。Riemann提供的各种处理过滤API,就相当于这个管网中的各种阀门和处理器,并把它们从这个主管道再送到各个子管网中去。

(图片来源于网络)
流被设计成无数的事件从它中间流过,但是没有却没有任何事件状态保留。但是我们出于对事件的控制,我们有时必须要对这些流过的事件状态有所记录,而对于这个事件状态的管理就是我们下面要说到的riemann索引(Index)。
索引(Index)
Riemann索引是一张表,它记录着所有被Riemann跟踪服务的事件的当前状态,每一个事件都有根据它的host和service进行分组后独一无二的索引。你可以告诉Riemann那些索引过的事件你想去跟踪,Riemann能通过这个事件的:host和:service值,去创建一个新索引并使用一个新的服务名。索引能保存最近事件为这个服务。
在上面的事件概念中,我们提到过每个事件必须有一个TTL项,它记录着每个事件应该保留多长时间有效,一旦这个事件在索引的时间超过这个TTL,Riemann将会把这个事件从它的索引移除,并重新插入一条state为“expired”的新事件到这个索引。
怎样学习和使用Riemann
我在每一次接触Riemann的时候,那可是一个头大。一来,国内外介绍Riemann的资料还不是很多,它最好最全资料就是它的官网文档http://riemann.io/howto.html,但是全英文的文档对于我们这些英语不是母语的人来说,自然看的不是太顺畅。二来,Rirmann的配置其实就是一个小型的clojure程序。
很多网友可能知道clojure其实是lisp的一种方言,并且也听说了这种语言的各种弊端和难懂(其实它也有很多其它语言所没有的优点,不然lisp这种语言也不会存活近60年还不断有新的方言出现,并一直有人在使用,由于这篇文章不是介绍lisp的,有兴趣的网友可以自己去网上查看lisp的特点)。
不过大家不用担心,Riemann并不是想让大家成为一个clojure专家,它只要大家掌握一些clojure的基础知识和基本的数据类型和结构就行。Riemann已经为大家封装好了大部分好用和常用的API,我们只要简单的去调用这些API就行了。
下面我们就来看看Riemann有那些好用的API。这也是Riemann很少一部分API的展示,但也足以展示Riemann的强大功能。
where: 事件过滤,我们可以根据where中的条件,将主流中的事件过滤到它的子流中并单独处理。
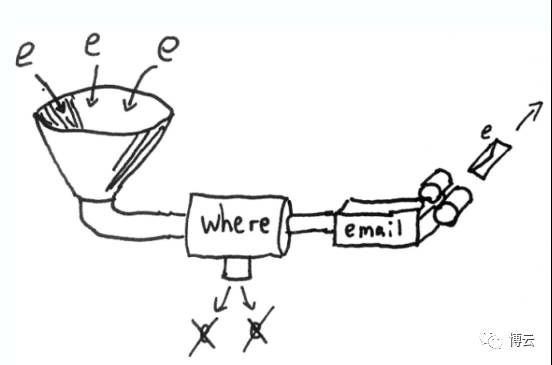
例子代码:
(streams (where (and (service #”^cpu”)
(state “danger”))
(<自己的一些对cpu监控告警的处理>)))
by: 它就像是管网中的三角阀,可以让事件在流中分组,不同的事件项的值,流入到不同的子流中去。下面这个图就展示了,不同host和service的事件分组到不同的子流中进行处理。
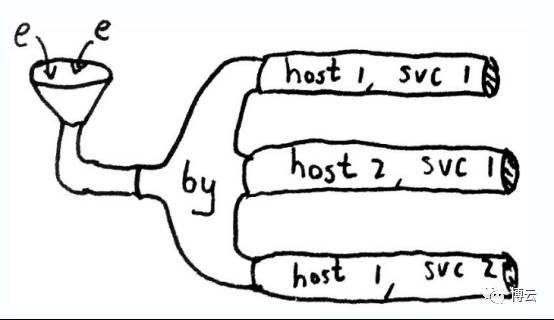
例子代码:
(where (tagged “bsm_colloted”)
(by [:host :service]
(rate 10 index)))
changed: 对于主机进行监控的时候,有时相似的监控事件会不停的从被监控主机发来,我们有时并不想把这种相同的事件不断的处理,只想把相同的事件只处理一次,只有它再次变化的时候再去处理。这时,这个API就可以用到了,它仅仅发现事件中检查项的值变化后,才会把这个事件发送到子流中进行处理,否则不对这个事件做任何处理。
例子代码:
(by [:host :service]
(changed :state))
rollup: 如果对于一个监控事件,我们1小时就能收到几百甚至上万条,而实际上我们仅仅想处理或是发送5条给客户,这个API就可以起到事件聚合的作用,先发4条事件给客户或流入子流中,然后把其余的事件缓存起来,等到1小时结束的时候才把最后一条事件发出。
例子代码:
(by [:host :service]
(rollup 5 3600
(email "user_one@mailbox.com")))
上面仅仅很少但是很能代表riemann功能的API,更多详细的API,大家可以查阅文档:http://riemann.io/api.html。
Riemann性能和高可用设计
作为之前提到的,Riemann在运行过程要需要很大的内存支撑。我们应该尽可能选用大内存的机器去运行Riemann。另外,Riemann是运行在JVM上的,于是你可以在启动Riemann之前,就提前配置好附加的Java堆内存给它。这个配置文件在/etc/sysconfig/riemann(Red hat)/etc/default/riemann(Ubuntu)。下面是一个例子,具体配多少取决于机器的实际情况。
# Optional JAVA_OPTS
EXTRA_JAVA_OPTS="-Xms4096m -Xmx4096m"
Riemann对事件的流处理方式,就决定了它同一主机的事件不可能在多个Riemann中进行处理或是同步,也就是说它无法支持集群。那怎样在生产环境中实现高可用呢?我们现在只能找一些替代的解决办法,比如HAproxy,我们可以安装几个Riemann在我们后端主机池中,一旦目前在用的Riemann宕机,其它的一个备用Riemann将去代替。
上面对于Riemann的一些认识和使用经验。如果大家有什么问题或者不同的见解,欢迎大家一起讨论。


