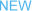

随着存储技术的发展,分布式存储在可靠性、可扩展性、可维护性以及成本上相对传统存储系统具有不可比拟的优势。尤其是在云计算中海量业务数据、容量按需扩展的场景下,分布式存储得到越来越广泛的应用。
分布式存储系统中需要解决的一个重要问题就是在系统容量逐步增加的过程中,如何平衡数据分布和负载、最大化系统性能、并处理系统扩展和硬件失效。这就是分布式存储系统的核心问题之一:数据分布算法。好的数据分布算法能够很好的处理这些问题。
本文主要介绍两种分布式存储的数据分布算法:一致性哈希和CRUSH算法。
一致性哈希算法
1.核心思想
一致性哈希算法(Consistent Hashing)最早在1997年由MIT的Karger提出,这种算法很好的解决了在某个节点系统故障时,使用简单取余哈希算法(hashk = k % N)时由于哈希表大小(N)变化而导致的几乎所有节点上的数据迁移[1]。
一致性哈希算法使用常用哈希函数将key和节点分别映射到具有2^32个桶空间中,即0~2^32-1的空间中。将0和2^32-1看做相邻,则这些桶可以想象成一个闭合的环。如下图1:

图1 哈希空间(环)
将key和node也映射到这个环上,如图2:
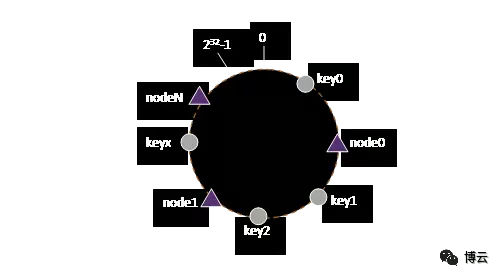
图2 节点和对象在映射到哈希环
映射完成之后,数据分布就比较容易了,按照顺时针方向,对于任意一个key,在哈希环上找到第一个node,那么这个key就应该保存在这个node上。对于图2,key0保存在node0,key1和key2保存在node1,keyx保存在nodeN上。
选择合适的哈希函数,使key和node均匀的映射到0~232-1上,则数据就能够均匀的分布到各个节点。
简单哈希取余算法的最大缺点就是在节点加入和离开时造成大量位置失效,从而产生大量数据迁移。一致性哈希对这个问题是这样处理的:例如,假设node0失效,那么key0就映射到顺时针离它最近的新节点node1上。也就是说,只有原来映射到node0上的对象映射位置失效而发生数据迁移,但是对于系统中的其他节点上的对象,映射位置并未发生变化,也不会发生数据迁移。同理对于新节点加入,只有映射到新加入节点上的对象需要迁移,其他对象由于映射的节点不变,也不会发生数据迁移。
2.存在问题及优化
当节点较少的时候,节点在哈希环上的映射可能不均匀,为此可以做一些优化。例如引入虚节点vnode,每个物理节点被看待为包含若干个虚节点的节点,通过设置虚节点的数目实现对象的均匀分布。
哈希函数一旦确定,数据归属的位置就确定了,如果想在运行时指定数据的存放位置,这种算法就难以实现。
3.算法的应用
一致性哈希算法在工业界得到了广泛的应用,例如分布式对象存储swift、分布式文件存储GlusterFS、分布式块存储sheepdog等。
CRUSH算法
1.核心思想
CRUSH是开源分布式存储ceph中使用的一种数据分布算法,它的全称是Controlled Replication Under Scalable Hashing,被实现为一个伪随机的确定性函数[2]。在这种算法下,使得ceph不仅能够轻松处理硬件失效、水平扩展等海量数据存储中的常见问题,还能够允许管理员依据需要精确指定数据的存储位置。
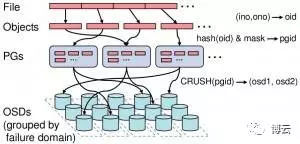
图3 Ceph寻址示意图[3]
图3描述了Ceph如何定位一个文件应该存储在集群中的具体位置。这里假设需要保存一个名为File的文件,如果该文件大于4M,则会被切分为多个大小为4M(默认值)的object(最后一个可以小于4M),其id(即oid)依次为:File0,File1……每个oid会根据一个静态hash函数映射到一个PG。这样,就完成了从File到PG的映射过程,可以看出,该过程是静态的,不会随着集群的扩容、组件故障变化而改变。但是PG只是逻辑单元,真正存储数据的是OSD,而从PG到OSD的映射,即为CRUSH算法的所需要做的。
简单的说,CRUSH的作用就是,在当前集群状态和存储规则下,根据PGid计算出一个OSD列表。存储规则一般不会经常变化,而集群当前状态,则可能因磁盘损坏、节点宕机等时刻变化。当节点因宕机或者重启而离开或者加入集群时,对象映射的OSD列表随之变化,数据就会从旧的OSD上迁移到新的OSD,该过程都是自动完成的,无需人工干预。
2.工作流程
ceph的数据分布主要由两个因素决定:cluster map和data distribution policy。cluster map描述了集群资源的层级结构,例如有几个机房,每个机房有几个机架,每个机架中几个服务器,每个服务器上几块磁盘。而data distribution policy由placement rules组成,rule决定了数据的存储策略,例如每个数据要存多少个副本,这些副本的存储限制(例如3个副本要存储在不同的机架或者3个不同主机)等。
cluster map由device和bucket组成,device一般是磁盘,为实际数据的载体,bucket则包含一个或者多个item,每个item可以是device,也可以是其他bucket。它们是对集群硬件拓扑的逻辑重划分。算法流程主要包含三个步骤[2]:
take(a) 选择一个存储层次上的item(一般为bucket),组成向量i,作为下一步的输入;
select(n, t) 迭代向量i中的每个元素,在其子树中伪随机的选择n个不同的类型为t的item;
输出结果
理论描述比较枯燥,有兴趣可以直接查看Sage的论文[2],这里不做过多描述。下面以一个实际例子来说明如何在生产中通过配置CRUSH来实现业务需求。
3.生产环境如何配置CRUSH
如果使用某些“入门手册”之类的部署了ceph集群,并不需要自己手动配置CRUSH视图,部署工具生成了默认的的CRUSH MAP,它列出了集群中的OSD设备,并将OSD所在的主机声明为桶。
在实际生产环境中,为了保证数据安全,我们会将集群存储节点放置到由不同电源供电的机架中,甚至不同的机房中,以保证数据的安全性和可用性。也可能需要一个存储集群为不同业务提供不同性能的存储。这时就需要根据实际业务需要定制CRUSH MAP。
这里以一个实际例子,说明如何配置CRUSH MAP以达到上述要求。假设集群硬件拓扑图如图4所示:
图4 硬件拓扑示意图
有2个机房room1和room2,其中room1有2个机架rack1-1、rack1-2,room2有一个机架rack2-1。机架中的主机挂载两种类型的存储介质,一种使用的是普通机械HDD硬盘,另一种使用SSD盘。
我们的目标是,使集群能够对外提供两种不同IO性能的存储,从而使得上层应用能够依据自身业务类型选择不同类型的存储。同时,要求集群中的数据具有尽可能高的安全性和可用性。
这里有三个机架,我们就用三副本策略利用CRUSH MAP让任意一份数据在三个机架中都有一个完整备份。在这种模式下,系统最大可以容忍一个机架上的所有存储节点全部宕机,且仍然能够对外提供服务,保证数据安全。当然对于一个或者多个磁盘损坏、某些节点宕机,在ceph集群看来就完全属于正常现象,其能够自动处理硬件故障时的数据迁移,无需人工干预。
部署好集群后,我们开始设置CRUSH MAP,步骤如下:
①获取集群当前CRUSH MAP,保存为crush_map.o:

②反编译为文本文件crush_map.txt:

③定制CRUSH MAP。
根据我们的需求,修改crush_map.txt内容。
这里共有24台主机,将其分为两组,一组由配置HDD的主机组成,用于提供容量型存储池,另一组由配置SSD的主机组成,用于提供高性能的存储池。对于容量型存储池,为了将每一份数据存储在不同的机架,可以将机架定义为桶,并在存储规则中设置选定副本数目的桶类型为机架。使用同样的方法配置SSD主机,并将它们分别放在两颗不同的CRUSH树根节点(hdd_pool和ssd_pool)下,得到的文本crush_map.txt见附件。
这里可以指定room为桶,并将room放在根节点下,也可以不指定,因为我们的存储策略是希望数据存储在不同的机架中。如果希望每一份数据都存储在不同的room,则需要将room设置为桶。
④编译定制的CRUSH MAP保存为new_crush.o:

⑤将定制的CRUSH MAP导入到当前集群:

如果集群中已经保存有数据,修改CRUSH MAP后会发生数据迁移。因此建议在集群规划初期就规划好CRUSH MAP结构,以避免发生大规模长时间的数据迁移。
待集群稳定,使用ceph osd tree命令即可查看最新的osd tree:

可以看到,此时集群内定义了两颗CRUSH树,根节点分别为ssd_pool和hdd_pool,与之对应的是两条规则(附件crush_map.txt中):

在集群创建pool时,指定使用的规则即可。
例如,创建一个在HDD硬盘上的大容量存储池用于存储大文件:

在向这个pool写入数据时,依据该规则,将首先从hdd_pool这个根节点开始向叶子节点遍历,type类型为rack,副本数目为3,将依据CRUSH算法在host1-1-1和hdd1-1-2上共同保存一份,即rack1-1-hdd中。同时,另外两份数据分别保存在另外两个rack中的节点中。
创建一个使用SSD的高性能存储池:

类似的,在向high_perf_pool这个存储池写入数据时,依据CRUSH算法,3副本数据每份副本分别保存在三个rack中的配备SSD的存储节点中。
总结
本文简单介绍了两种业界常用的分布式系统数据分布算法,一致性哈希算法原理清晰易懂,能够很好的处理简单哈希算法在节点失效时大量数据迁移的问题,在业界得到广泛的应用;ceph中使用的CRUSH伪随机数据分布算法原理稍微复杂,但是拥有更大的灵活性,能够允许管理员精确的指定对象副本如何放置,以适应更多更复杂的应用场景。
参考资料
[1] https://en.wikipedia.org/wiki/Consistent_hashing
[2] http://ceph.com/papers/weil-crush-sc06.pdf
[3] http://www.csdn.net/article/2014-04-08/2819192-ceph-swift-on-openstack-m/2
附件:crush_map.txt的内容:
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable straw_calc_version 1
# devices
device 0 osd.0
device 1 osd.1
device 2 osd.2
device 3 osd.3
device 4 osd.4
device 5 osd.5
device 6 osd.6
device 7 osd.7
device 8 osd.8
device 9 osd.9
device 10 osd.10
device 11 osd.11
device 12 osd.12
device 13 osd.13
device 14 osd.14
device 15 osd.15
device 16 osd.16
device 17 osd.17
device 18 osd.18
device 19 osd.19
device 20 osd.20
device 21 osd.21
device 22 osd.22
device 23 osd.23
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 region
type 10 root
# hdd host in rack1-1
host hdd1-1-1 {
id -1
alg straw
hash 0 # rjenkins1
item osd.0 weight 2.0
item osd.1 weight 2.0
}
host hdd1-1-2 {
id -2
alg straw
hash 0 # rjenkins1
item osd.2 weight 2.0
item osd.3 weight 2.0
}
# hdd host in rack1-2
host hdd1-2-1 {
id -3
alg straw
hash 0 # rjenkins1
item osd.4 weight 2.0
item osd.5 weight 2.0
}
host hdd1-2-2 {
id -4
alg straw
hash 0 # rjenkins1
item osd.6 weight 2.0
item osd.7 weight 2.0
}
# hdd host in rack2-1
host hdd2-1-1 {
id -5
alg straw
hash 0 # rjenkins1
item osd.8 weight 2.0
item osd.9 weight 2.0
}
host hdd2-1-2 {
id -6
alg straw
hash 0 # rjenkins1
item osd.10 weight 2.0
item osd.11 weight 2.0
}
# ssd host in rack1-1
host ssd1-1-1 {
id -7
alg straw
hash 0 # rjenkins1
item osd.12 weight 1.0
item osd.13 weight 1.0
}
host ssd1-1-2 {
id -8
alg straw
hash 0 # rjenkins1
item osd.14 weight 1.0
item osd.15 weight 1.0
}
# ssd host in rack1-2
host ssd1-2-1 {
id -9
alg straw
hash 0 # rjenkins1
item osd.16 weight 1.0
item osd.17 weight 1.0
}
host ssd1-2-2 {
id -10
alg straw
hash 0 # rjenkins1
item osd.18 weight 1.0
item osd.19 weight 1.0
}
# ssd host in rack2-1
host ssd2-1-1 {
id -11
alg straw
hash 0 # rjenkins1
item osd.20 weight 1.0
item osd.21 weight 1.0
}
host ssd2-1-2 {
id -12
alg straw
hash 0 # rjenkins1
item osd.22 weight 1.0
item osd.23 weight 1.0
}
# bucket hdd rack1-1
rack rack1-1-hdd {
id -13
alg straw
hash 0
item hdd1-1-1 weight 4.0
item hdd1-1-2 weight 4.0
}
# bucket hdd rack1-2
rack rack1-2-hdd {
id -14
alg straw
hash 0
item hdd1-2-1 weight 4.0
item hdd1-2-2 weight 4.0
}
# bucket hdd rack2-1
rack rack2-1-hdd {
id -15
alg straw
hash 0
item hdd2-1-1 weight 4.0
item hdd2-1-2 weight 4.0
}
# bucket ssd rand1-1
rack rack1-1-ssd {
id -16
alg straw
hash 0
item ssd1-1-1 weight 2.0
item ssd1-1-2 weight 2.0
}
# bucket ssd rack1-2
rack rack1-2-ssd {
id -17
alg straw
hash 0
item ssd1-2-1 weight 2.0
item ssd1-2-2 weight 2.0
}
# bucket ssd rack2-1
rack rack2-1-ssd {
id -18
alg straw
hash 0
item ssd2-1-1 weight 2.0
item ssd2-1-2 weight 2.0
}
root hdd_pool {
id -19
alg straw
hash 0 # rjenkins1
item rack1-1-hdd weight 8.0
item rack1-2-hdd weight 8.0
item rack2-1-hdd weight 8.0
}
root ssd_pool {
id -20
alg straw
hash 0 # rjenkins1
item rack1-1-ssd weight 4.0
item rack1-2-ssd weight 4.0
item rack2-1-ssd weight 4.0
}
# rules
rule hdd_pool_rule {
ruleset 0
type replicated
min_size 1
max_size 10
step take hdd_pool
step chooseleaf firstn 0 type rack
step emit
}
rule ssd_pool_rule {
ruleset 1
type replicated
min_size 1
max_size 10
step take ssd_pool
step chooseleaf firstn 0 type rack
step emit
}
# end crush map


