
随着 Kubernetes 越来越成熟,以 kubernetes 为基础构建基础设施层的企业越来越多。据 CNCF 基金会统计,目前使用 Kubernetes 作为容器管理工具的企业占比早已过半,并且远远超过排名第二的 Swarm。
伴随着 Kubernetes 的使用越来越多,过程中也逐渐发现了一些问题,并促进了 kubernetes 联邦集群的发展。这些问题主要包括:
1、kubernetes集群自身限制
根据kubernetes官方大规模集群注意事项,以最新版本Kubernetes v1.24 为例我们可以看到kubernetes集群存在以下限制:
· 节点数不超过5000
· 每个节点的Pod数量不超过110个
· Pod总数不超过150000
· 容器总数不超过300000
由于单个集群的限制,有些业务可能需要部署在大量的Kubernetes集群上,此时就需要对多集群进行管理。
2、多集群管理的强烈需求
首先,将业务部署在单个的大规模集群中是比部署在多个较小集群中危险的,例如单个大集群出现故障,无法进行故障转移。其次,通过联邦集群可以在集群间进行资源同步和跨集群的服务发现,例如同城双活的场景。
鉴于以上(不限于)多种原因,企业内的 K8S 集群数量越来越多,K8S 自身的管理也变得日益复杂。
01 kubernetes联邦集群的发展史
为了解决上述问题,kubernetes 兴趣小组最初推出了项目 kubefed v1。Kubefed v1 在Kubernetes v1.6 时进入了 Beta 阶段,然而 kubefed v1后续的发展不尽人意,最终在 Kubernetes v1.11 左右正式被弃用,弃用的主要原因是因为它存在以下问题:
- 控制平面组件会因为发生问题,而影响整体集群效率。
- 无法兼容新的 Kubernetes API 资源。
- 无法有效的在多个集群管理权限,如不支持 RBAC。
- 联邦层级的设定与策略依赖 API 资源的 Annotations 内容,这使得弹性不佳
kubernetes 兴趣小组并没有放弃发展 kubernetes 联邦集群, 后来升级版的kubefed v2 出现了,kubefed v2 解决了兼容新的 kubernetes API 资源的问题,通过 CRD 扩充可支持的资源,并将集群划分为 Host 和 Member 两种类型的集群:
- Host :用于提供 KubeFed API 与控制平面的集群。
- Member :通过 KubeFed API 注册的集群,并提供相关身份凭证来让 KubeFed Controller 能够连接集群。Host 集群也可以作为 Member 被加入。
继V1版本之后,社区又推出了Kubefed V2。相比于kubefed v1, V2有了巨大的改变,例如对 kubernetes 原生资源分发的支持更加灵活,可以支持多个版本的API,弥补了kubefed v1无法兼容新 API 的缺点,另外还支持了 CRD 自身,通过 Placement 字段配置资源分发,通过 Overrides 字段可以差异化配置分发到不同集群的资源。然而 kubefed v2 在推广过程中出现了以下问题:
例如部署deployment:
apiVersion: types.kubefed.io/v1beta1 kind: FederatedDeployment #自定义资源类型 metadata: name: test-deployment namespace: test-namespace spec: template: #要部署的资源模板 metadata: labels: app: nginx spec: replicas: 1 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - image: nginx name: nginx placement: # 对象需要部署到集群member1和member2 clusters: - name: member1 - name: member2 overrides: # 修改部署到member2集群的副本数为2 - clusterName: member2 clusterOverrides: - path: "/spec/replicas" value: 2
- 需要通过遍历集群才能获取部署的应用的具体状态,在控制面只能看到应用是否分发成功。
经历了多年发展,联邦集群这个领域的两次尝试都算不上成功。 难道就没有一个更好用的项目用来管理 kubernetes 联邦集群吗?
此时社区中的另一个项目 karmada 初露头角,karmada 继承和改进了kubefed,例如部署 deployment, 在 karmada 中 FederatedDeployment 被拆解成了三个单独的资源,分别是资源模板 resource template 是Kubernetes 原生 API 使用起来更舒服, 调度策略 propagation policy 和差异化配置策略 override policy。
02 Karmada 架构
以 karmada v1.2.0 版本为例,karmada的结构如下图所示:
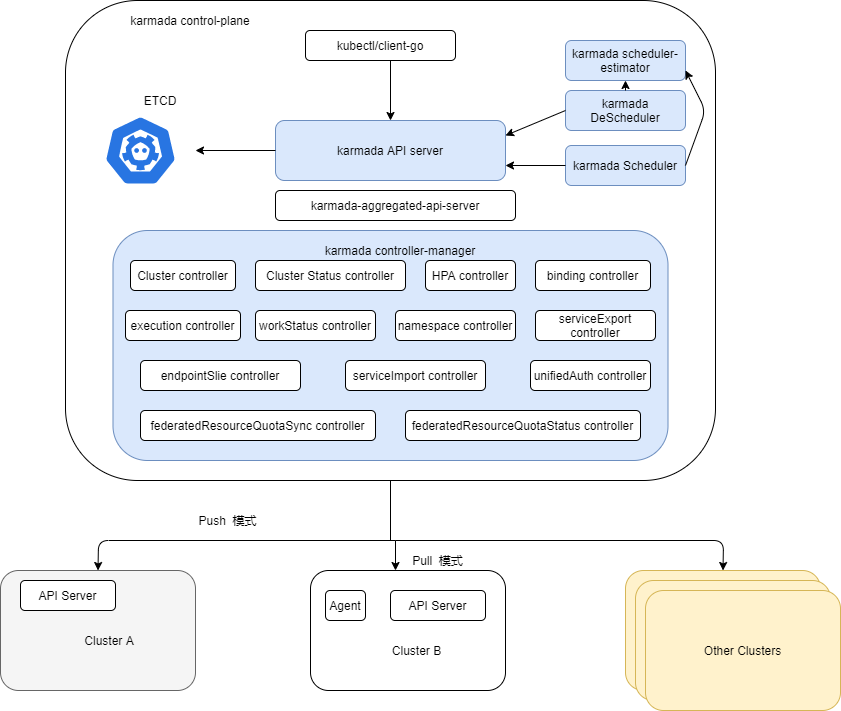
其中的 karmada controller-manager,karmada aggregated-api-server,karmada Scheduler,karmada DeScheduler,karmada scheduler-estimator, karmada Agent是karmada官方开发的组件,ETCD 即 ETCD官方镜像,karmada API server 是 Kubernetes 官方的 API server 组件镜像。
- karmada API server 与 API server 在 Kubernetes 集群中的功能类似,用来处理资源的增删改查及将数据持久到 ETCD 中。
- karmada controller-manager 功能是管理karmada 中的实现的controllers,负责它们的启动和停止等。
- karmada aggregated-api-server 是一个聚合API,该组件实现了通过karmada API server 即可访问成员集群资源的功能,并实现了统一鉴权认证,不用切换 kubeconfig 即可访问不同成员集群。
- karmada Scheduler 实现了 karmada 对资源调度到成员集群的调度功能,并实现了多种调度策略。
- karmada DeScheduler 实现了每隔一段时间就检测一次所有部署,将目标集群中不可调度的副本再调度到其他可调度的集群上。
- karmada scheduler-estimator 用来评估成员集群上可调度的副本数,在一些调度策略中调度器将根据其计算副本数来计算每个目标集群上需要调度的副本数。
- karmada Agent 是部署在成员集群上的组件,用来上报成员集群信息到 karmda 控制平面和从 karmada 控制平面拉取分发到成员集群的资源信息。
03 Karmada 相关资源概念
下面我们简单介绍一下 karmada 分发资源到成员集群涉及的相关资源,这些资源可分为:
用于设定策略的资源:PropagationPolicy,OverridePolicy。
执行策略相关的资源:ResourceBinding,ClusterResourceBinding, Work。
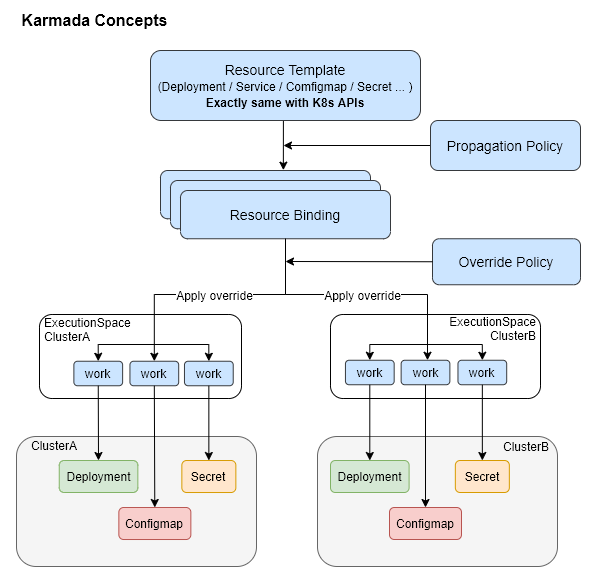
karmada 分发资源到成员集群流程如上图所示, 在 karmada 控制平面创建Resource Template 即为kubernetes原生资源,例如 Deployment,Service, configmap 等资源,同时创建 Propagation Policy 资源用来描述分发 Resource Template 到成员集群的策略,例如描述调度到哪些成员集群,使用静态权重策略等,如果有需要同时也可以创建Override Policy用来覆盖分发到不通成员集权中Resource Template中某些字段,例如修改Deployment中的容器镜像地址,容器参数等。
BindingController 根据 Resource Binging 资源内容创建 work 资源到各个成员集群的执行命名空间, work 中描述了要分到目标集群的资源内容,最终由ExeuctionController 在各个成员集群中创建被分发的资源。
PropagationPolicy
分发策略包含集群级别的 ClusterPropagationPolicy 和 Namespace 级别的PropagationPolicy,集群级别的可以分发各个命名空间的 resource Template,namespace 级别的只能分发自己命名空间级别的 resource Template,用来定义将创建的 resource Templater 分发到成员集群的策略。
我们详细看一下该资源相应字段:
Spec :
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| ResourceSelectors | []ResourceSelector | 是 | 用于筛选资源 |
|
| Association | bool | 否 | 已弃用 |
|
| PropagateDeps | bool | 否 | 是否自动传播相关资源,例如deployment引用configmap,设置为true时,可以从ResourceSelectors中省略引用的资源,在故障转移场景中也将一起被转移。 | 默认false |
| Placement | Placement | 否 | 选择集群分发资源的规则 |
|
| DependentOverrides | []string | 否 | OverridePolicy列表,当前namesapce中的OverridePolicy和ClusterOverridePolicy如果与要分发的资源匹配,即使不在此列表中也会生效。 |
|
| SchedulerName | string | 否 | 指定scheduler,否则使用默认scheduler |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| APIVersion | string | 是 | 目标资源的 API version |
|
| Kind | string | 是 | 目标资源的kind |
|
| Namespace | string | 否 | 目标资源的namespace |
|
| Name | string | 否 | 目标资源的name |
|
| LabelSelector | *metav1.LabelSelector | 否 | 通过label筛选资源集,name不为空时忽略该值 |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| ClusterAffinity | *ClusterAffinity | 否 | 表示对特定集群集的调度限制。如果未设置,任何集群都可以成为调度候选者。 |
|
| ClusterTolerations | []corev1.Toleration | 否 | 集群 tolerations(容忍度) |
|
| SpreadConstraints | []SpreadConstraint | 否 | 调度约束列表,定义应用分发的HA策略 |
|
| ReplicaScheduling | *ReplicaSchedulingStrategy | 否 | 在将具有规范副本的资源(例如deployments、statefulsets)传播到成员集群时处理副本数量的调度策略。 |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| LabelSelector | *metav1.LabelSelector | 否 | LabelSelector 是一个按标签选择成员集群的过滤器。如果non-nil且non-empty,则仅选择匹配此过滤器的集群。 |
|
| FieldSelector | *FieldSelector | 否 | 通过字段来选择成员集群。如果non-nil且non-empty,只有匹配这个过滤器的集群才会被选中。 |
|
| ClusterNames | []string | 否 | 要选择的集群name列表。 |
|
| ExcludeClusters | []string | 否 | 要忽略的集群列表。 |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| SpreadByField | SpreadFieldValue | 否 | 代表karmada动态的将成员集群分成不同的组的字段,资源将被分发到不同的集群组中,该字段可以是cluster, region,zone, provider,该字段不应与SpreadByLabel共存,两者都为空时,SpreadByField默认为cluster。 |
cluster, region, zone, provider |
| SpreadByLabel | string | 否 | 表示将成员集群分成不通组所用的label,资源将被分发到不同的集群组。 |
|
| MaxGroups | int | 否 | 限制要选择的集群组的最大数量。 |
|
| MinGroups | int | 否 | 限制要选择的集群组的最小数量。 |
|
Spec.Placement.ReplicaSchedulingStrategy:
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| ReplicaSchedulingType | ReplicaSchedulingType | 否 |
ReplicaSchedulingType 确定在 karmada 传播资源时如何调度副本。有效的选项是Duplicated和Divided。“Duplicated”将相同的副本从资源复制到每个候选成员集群。 “Divided”根据有效候选成员集群的数量将副本划分为多个部分,每个集群的确切副本由 ReplicaDivisionPreference 确定。 |
Duplicated,Divided |
| ReplicaDivisionPreference | ReplicaDivisionPreference | 否 |
ReplicaDivisionPreference 确定如何划分副本,当 ReplicaSchedulingType 为“Divided”时。 有效选项是Aggregated 和Weighted。 “Aggregated ”将副本划分为尽可能少的集群,同时在划分期间尊重集群的资源可用性。 “加Weighted”根据 WeightPreference 按weight 划分副本。 |
Aggregated,Weighted |
| WeightPreference | *ClusterPreferences | 否 | WeightPreference 描述每个集群或每组集群的权重 如果 ReplicaDivisionPreference 设置为“Weighted”,并且未设置 WeightPreference,调度程序将对所有集群进行相同的加权。 |
|
Spec.Placement.ClusterAffinity.FieldSelector :
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| MatchExpressions | []corev1.NodeSelectorRequirement |
|
字段选择器要求列表。 |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| StaticWeightList | []StaticClusterWeight | 否 | 定义静态集群权重。 |
|
| DynamicWeight | DynamicWeightFactor | 否 | DynamicWeight 指定生成动态权重列表的因素。如果指定,StaticWeightList 将被忽略。 | 当前只支持AvailableReplicas |
DynamicWeightByAvailableReplicas 表示应根据可用资源(可用副本)生成集群权重列表。
// Example:
// The scheduler selected 3 clusters (A/B/C) and should divide 12 replicas to them.
// Workload:
// Desired replica: 12
// Cluster:
// A: Max available replica: 6
// B: Max available replica: 12
// C: Max available replica: 18
// The weight of cluster A:B:C will be 6:12:18 (equals to 1:2:3). At last, the assignment would be 'A: 2, B: 4, C: 6'.
Spec.Placement.ReplicaSchedulingStrategy.WeightPreference.StaticClusterWeight:
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| TargetCluster | ClusterAffinity | 是 | 用于选择集群的过滤器。 |
|
| Weight |
|
|
|
|
OverridePolicy
OverridePolicy 和 ClusterOverridePolicy 定义下发到不通成员集群中不通配置,karmada支持的有:
- ImageOverrider 覆盖工负载的镜像
- CommandOverrider 覆盖工作负载的 commands
- ArgsOverrider 覆盖工作负载的 args
- PlaintextOverrider 通用工具,覆盖任何种类的资源
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| ResourceSelectors | []ResourceSelector | 否 |
限制了此覆盖策略适用的资源类型。nil 表示匹配所有资源。 (字段结构同PropagationPolicy) |
|
| OverrideRules | []RuleWithCluster | 否 | 定义目标集群上的覆盖规则集合。 |
|
| TargetCluster | *ClusterAffinity | 否 | 定义了对此覆盖策略应用到成员集群的目标选择。nil 表示匹配所有集群。(字段同PropagationPolicy) |
|
| Overriders | Overriders | 否 | Overriders 表示将应用于资源的覆盖规则,已弃用,请使用OverrideRules |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| TargetCluster | *ClusterAffinity | 否 |
定义了对此覆盖策略应用到成员集群的目标选择。nil 表示匹配所有集群。 (字段同PropagationPolicy) |
|
| Overriders | Overriders | 是 | 应用于资源的覆盖规则 |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| ImageOverrider | []ImageOverrider | 否 | 覆盖镜像的规则 |
|
| Plaintext | []PlaintextOverrider | 否 | 覆盖规则 |
|
| CommandOverrider | []CommandArgsOverrider | 否 | 容器command覆盖规则 |
|
| ArgsOverrider | []CommandArgsOverrider | 否 | 容器arg覆盖规则 |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| Predicate | *ImagePredicate | 否 |
默认为nil, 如果资源是Pod, ReplicaSet, Deployment, StatefulSet系统自动检测镜像,如果资源对象有多个容器,所有镜像都将被处理。如果不为空,则只处理匹配到的镜像。 |
|
| Component | ImageComponent | 是 |
假设镜像组成成分: [registry/]repository[:tag] |
Registry,Repository,Tag |
| Operator | OverriderOperator | 是 | 对镜像进行的操作 | add,remove,replace |
| Value | string | 否 | 当Operator为'add'或'replace'时不能为空,默认为空,当operator为remove时忽略。 |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| Path | string | 是 | 目标字段的路径 | /spec/template/spec/containers/0/image |
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| Path | string |
|
目标字段的路径 |
|
| Operator | OverriderOperator |
|
对目标字段操作类型 | add,remove,replace |
| Value | apiextensionsv1.JSON | 否 | 应用在目标字段的值,当Operator为remove时,此字段必须为空 |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| ContainerName | string | 是 | 容器名 |
|
| Operator | OverriderOperator | 是 | 应用在commad/args上的操作 | add;remove |
| Value | []string | 否 | 应用在command/args上的值,当operator为add时该值append到commad/args,当operator为remove时,该值从command/args移除,如果该值为空command/args维持原状。 |
|
ResourceBinding 是由控制器 ResourceDetector 根据 resource Template 和Propagation Policy 的内容自动创建的资源,代表一个 kubernetes 资源和一个分发策略的绑定,与分发策略相对应 ResourceBinding 也分为集群级别的ClusterResourceBinding 和 Namespace 级别的 ResourceBinding,同时也会记录 resource Template 最中部署的状态和结果。具体字段如下:
Spec:
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| Resource | ObjectReference | 是 | 被分发的kubernetes资源 |
|
| PropagateDeps | bool | 否 | 引用资源是否被自动分发,继承自PropagationPolicy |
|
| ReplicaRequirements | *ReplicaRequirements | 否 | 每个replica的需求 |
|
| Replicas | int32 | 否 | 副本数 |
|
| Clusters | []TargetCluster | 否 | 目标成员集群 |
|
| RequiredBy | []BindingSnapshot | 否 | 引用资源的Bindings列表 |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| APIVersion | string | 是 | 资源API version |
|
| Kind | string | 是 | 资源Kind |
|
| Namespace | string | 否 | 资源Namespace |
|
| Name | string | 是 | 资源Name |
|
| UID | string | 否 | 资源UID |
|
| ResourceVersion | string | 否 | 资源ResourceVersion |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| NodeClaim | *NodeClaim | 否 |
表示每个副本所需的节点声明 HardNodeAffinity、 NodeSelector 和 Tolerations。 |
|
| ResourceRequest | corev1.ResourceList | 否 | 每个副本所需的资源请求 |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| HardNodeAffinity | *corev1.NodeSelector | 否 | 请注意,此处仅包含 PodSpec.Affinity.NodeAffinity中 RequiredDuringSchedulingIgnoredDuringExecution因为它对 Pod 调度有硬性限制。 |
|
| NodeSelector | map[string]string | 否 | 节点选择器,匹配要调度的到的Node的label |
|
| Tolerations | []corev1.Toleration | 否 | 容忍度 |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| Name | string | 是 | 目标集群名 |
|
| Replicas | int32 | 否 | 副本数 |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| Namespace | string | 否 | ResourceBinding的namespace |
|
| Name | string | 是 | RB或者CRB的名 |
|
| Clusters | []TargetCluster | 否 | 调度结果 |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| Conditions | []metav1.Condition | 否 | contain the different condition statuses |
|
| AggregatedStatus | []AggregatedStatusItem | 否 | 资源运行在每个子群上的状态列表 |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| ClusterName | string | 是 | 资源所部署处的集群 |
|
| Status | *runtime.RawExtension | 否 | 当前manifest运行状态 |
|
| Applied | bool | 否 | 资源是否成功的应用到集群中 |
|
| AppliedMessage | string | 否 | 应用失败的人类可读的错误信息 |
|
Work
work 定义了部署到目标成员集群的资源列表,由 bingingController 创建或者更新,由 execctionController 进行协调。
具体字段如下:
Spec:
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| Workload | WorkloadTemplate | 是 | 工作负载manifest |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| Manifests | []Manifest | 否 | 工作负载manifest |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| Manifest | runtime.RawExtension | 是 | 工作负载manifest |
|
Status:
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| Conditions | []metav1.Condition | 否 |
work不同情况的状态:1. Applied represents workload in Work is applied successfully on a managed cluster. 2. Progressing represents workload in Work is being applied on a managed cluster. 3. Available represents workload in Work exists on the managed cluster. 4. Degraded represents the current state of workload does not match the desired state for a certain period. |
|
| ManifestStatuses | []ManifestStatus | 否 | spec中的Manifest运作的状态 |
|
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| Identifier | ResourceIdentifier | 是 | Spec中manifest的身份 |
|
| Status | *runtime.RawExtension | 否 | manifest运行的状态 |
|
ResourceIdentifier:
| 字段 | 类型 | 必填 | 描述 | 示例 |
|---|---|---|---|---|
| Ordinal | int | 是 | manifests中的索引 |
|
| Group | string | 是 | 资源Group |
|
| Version | string | 是 | 资源Version |
|
| Kind | string | 是 | 资源Kind |
|
| Resource | string | 是 | 为空字符,资源类型 |
|
| Namespace | string | 是 | 资源Namespace |
|
| Name | string | 是 | 资源Name |
|
04 关注
在 karmada 的2022年的 roadmap 中,社区计划完善 Multi-cluster HA scheduling policy,联邦资源配额,及添加多集群日志、存储、RABC,管理,多集群监控等。本期文章先介绍那么多,后面我们也会持续关注 karmada 的发展,并再推出 karmada 更深入的介绍文章。


